
爬虫
教程来源1:https://www.bilibili.com/video/BV1Yh411o7Sz?p=14
教程来源2:https://www.bilibili.com/video/BV1xq4y1H7Ba/?p=50
爬虫简介
模拟浏览器,发送请求,获取响应
抓取互联网上的数据,为我所用。原则上,只要是客户端(浏览器)能做的事情,爬虫都能够做。爬虫也只能获取客户端(浏览器)所展示出来的信息。
- 比如没有登陆的账号,是获取不到会员数据的。如果有会员账号,理论上就可以。
有了大量的数据,就如同有了一个数据银行一样。
下一步做的就是如何将这些爬取的数据,产品化、商业化。
爬虫合法性探究
爬虫究竟是违法还是合法的?
- 在法律中不被禁止
- 具有违法风险
- 区分为善意爬虫和恶意爬虫
爬虫带来的风险
- 爬虫干扰了被访问网站的正常运营
- 爬虫抓取了受到法律保护的特定类型的数据或信息
如何避免进局子喝茶
- 时常优化自己的程序,避免干扰被访问网站的正常运行
- 在使用、传播爬取到的数据时,审查抓取的内容,如果发现了涉及到用户以及商业机密等敏感内容时,需要及时停止爬取或传播。
爬虫初始深入
爬虫在使用场景中的分类
根据被爬取网站的数量不同,可以分为:
通用爬虫
- 如搜索引擎
- 抓取系统的重要组成部分。
- 抓取的是一整张页面数据。
聚焦爬虫
- 是建立在通用爬虫的基础之上。
- 抓取的是页面中特定的局部内容。
根据是否以获取数据为目的,可以分为:
功能性爬虫
- 点赞、投票
增量式爬虫
- 检测网站中数据更新的情况。
- 只会抓取网站中最新更新出来的数据。
根据url地址和对应的页面内容是否改变,数据增量爬虫可以分为:
- 基于url地址变化、内容也随之变化的数据增量爬虫
- url地址不便,内容变化的数据增量爬虫
爬虫的矛与盾
- 反爬机制
- 门户网站,可以通过指定相应的策略或者技术手段,防止爬虫程序进行网站数据的爬取。
- 反反爬策略
- 爬虫程序,可以通过指定相关的策略或者技术手段,破解门户网站中具备的反爬机制,从而可以获取门户网站的和数据。
robots.txt协议
君子协议,规定了网站中哪些数据可以被爬虫爬取,哪些数据不可以被爬取。
http://www.baidu.com/robots.txt
爬虫作用
- 数据采集
- 抓取微博评论(机器学习舆情监控)
- 抓取招聘信息(数据分析、挖掘)
- 新闻资讯网站
- 软件测试
- 自动化测试:虫师 - 博客园 (cnblogs.com)
- 其他
- 抢票
- 投票
- 网络安全
- 短信轰炸
- web漏洞扫描:爬虫基础篇[Web 漏洞扫描器] (seebug.org)
爬虫基本流程
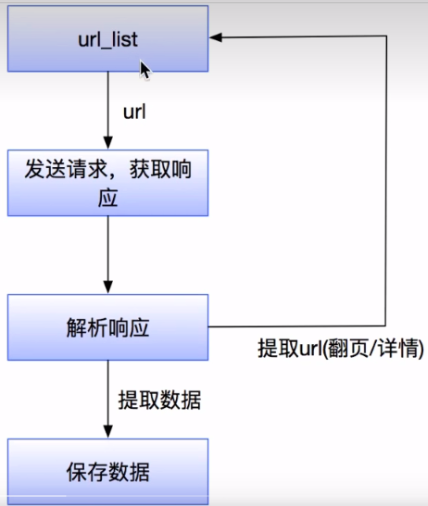
1.获取一个url
2.向url发送请求,并获取响应(需要http协议)
3.如果从响应中提取url,则继续发送请求获取响应
4.如果从响应中获取数据,则将数据进行保存
Http&Https协议
深入了解HTTP和HTTPS协议对提升爬虫能力是非常有帮助的,因为这些协议是在互联网上进行数据通信的基础。通过了解这些协议的工作原理和细节,你可以更有效地设计和实现爬虫,提高稳定性、效率和可靠性。以下是深入了解HTTP/HTTPS协议对提升爬虫能力的一些方面帮助:
- 请求和响应原理: 了解HTTP请求和响应的结构、头部信息、状态码等内容,能够帮助你构建更精确、有效的请求,以及处理服务器返回的数据。
- 请求方法和头部: 了解不同的HTTP请求方法(如GET、POST、PUT、DELETE等)以及各种头部字段(如User-Agent、Referer、Cookies等)的作用,有助于更好地模拟浏览器行为,防止被服务器拒绝访问。
- 状态码和错误处理: 熟悉HTTP状态码(如200、404、503等)的含义,可以帮助你更好地处理页面不存在、服务器错误等情况,从而提高爬取的稳定性。
- Cookies和Session: 了解Cookies的工作原理和使用方法,能够帮助你处理需要登录状态的网站,模拟用户会话,获取需要的数据。
- 重定向和URL处理: 理解HTTP重定向机制以及如何处理不同类型的重定向,能够让你更好地处理页面跳转和URL变化,确保爬虫不会陷入死循环或丢失数据。
- 代理和IP池: 通过了解代理服务器的使用和IP池的管理,可以提高爬虫的匿名性和稳定性,减少被目标网站封禁的风险。
- HTTPS加密通信: 了解HTTPS协议的加密通信原理,可以让你处理加密流量,确保数据的安全性,同时避免因为未知的证书问题而导致连接失败。
- 并发与异步: 熟悉HTTP/HTTPS的并发请求和异步处理机制,可以让你优化爬虫的性能,提高数据获取速度。
- 反爬虫机制: 了解网站常用的反爬虫技术,如验证码、限制频率等,可以帮助你设计更健壮的爬虫策略,规避被检测和封禁的风险。
- 数据解析: 理解HTTP响应中数据的格式(如HTML、JSON、XML等),能够更轻松地提取和解析所需数据,便于后续的处理和存储。
http协议
概念:超文本传输协议,默认端口号是80。就是服务器和客户端,进行数据交互的一种形式。
常用请求头信息:
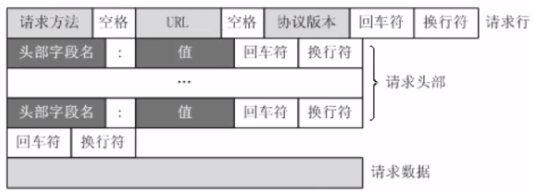
- User-Agent:浏览器名称,请求头的身份标识。
- Connection:链接类型。请求完毕后,是断开连接还是保持连接。
- Content-Type
- Host:主机和端口号
- Upgrade-Insecure-Requests:升级为HTTPS请求
- Referer:页面跳转处
- Cookie
- Authorization:用于表示HTTP协议中,需要认证资源的认证信息,如jwt认证
常用响应头信息:
- Content-Type:服务器响应回客户端的数据类型。
- Set-Cookie:对方服务器设置cookie到用户浏览器的缓存
http请求过程:
1.浏览器在拿到域名对应的ip后,先向地址栏中的url发起请求,并获取响应数据
2.在返回的响应(html)中,会拥有css、js、图片等url地址,以及ajax代码、浏览器按照响应内容中的顺序,依次发送其他请求,并获取相应的响应
3.浏览器每获取一个响应,就对展示出的结果进行添加(加载),js、css等资源会修改页面的内容,js也可以重新发送请求,获取响应
4.从获取第一个响应并在浏览器中展示,直到获取最终全部响应,并在展示的结果中添加内容或修改。这个过程叫做浏览器的渲染
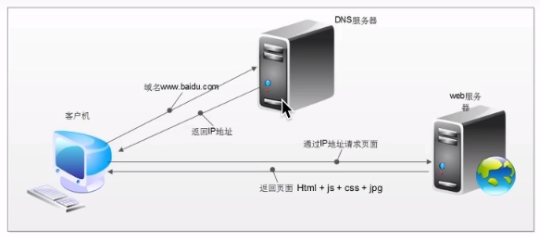
但是在爬虫中,爬虫只会请求url地址,对应的拿到url地址的响应(该响应的内容可以是html、css、js、图片等)
浏览器渲染出的页面和爬虫请求的页面很多时候并不一样,是因为爬虫不具备渲染的能力(可以借助其他工具包来对响应内容进行渲染)
- 浏览器最终展示结果,是由多个url地址,分别发送的多次请求,对应的多次响应共同渲染的结果
- 在爬虫中,需要以发送请求的一个url地址对应的一个响应为准,来进行数据的提取
HTTP请求过程:
HTTP(Hypertext Transfer Protocol)是一种用于在Web浏览器和Web服务器之间传输数据的协议。下面是HTTP请求的详细过程:
- DNS解析: 在发送HTTP请求之前,首先需要将域名解析为IP地址,以便确定目标服务器的位置。系统通过DNS(Domain Name System)查询来获取目标服务器的IP地址。
- 建立TCP连接: 使用解析得到的IP地址,客户端开始与目标服务器建立TCP连接。这个过程通常涉及三次握手,确保双方都能够通信。
- 构建HTTP请求: 客户端构建HTTP请求报文,包括请求行、请求头部和请求体。请求行包含请求方法(GET、POST等)、请求的URL路径以及HTTP协议版本。
- 发送HTTP请求: 客户端将构建好的HTTP请求报文发送给服务器,通过之前建立的TCP连接传输到服务器端。
- 服务器处理请求: 服务器收到请求后,开始处理请求。这可能包括验证、授权、生成响应等步骤。
- 服务器发送HTTP响应: 服务器构建HTTP响应报文,包括状态行、响应头部和响应体。状态行包含HTTP协议版本、状态码以及状态描述。
- 传输HTTP响应: 服务器将构建好的HTTP响应报文通过之前建立的TCP连接发送回客户端。
- 接收响应: 客户端接收到HTTP响应报文后,开始解析响应,提取响应头部和响应体。
- 处理响应: 客户端根据响应头部中的信息(如状态码)来判断请求是否成功。如果是成功响应,客户端可能会对响应体进行数据解析。
- 关闭连接: 一旦HTTP请求和响应过程完成,客户端和服务器之间的TCP连接可能会关闭,根据需要决定是否保持持久连接以减少连接建立的开销。
需要注意的是,这只是HTTP请求过程的一般流程,实际中可能会有更多的细节和步骤。此外,还有一些高级概念,如持久连接(Keep-Alive)、流水线化(Pipeline)、连接池(Connection Pooling)等,可以进一步优化HTTP请求的性能和效率。
https协议
- 概念:安全的超文本传输协议。
- 加密方式:
- 对称密钥加密
- 非对称密钥加密
- 证书密钥加密
关于http/https的其他参考阅读
- 自己找资料
- https://baike.baidu.com/item/http/243074?fr=aladdin
- https://www.jianshu.com/p/cc1fea7810b2
- https://blog.csdn.net/qq_30553235/article/details/79282113
- https://segmentfault.com/q/1010000002403462
常见响应状态码
- 200:成功
- 302:跳转,新的url在响应的Location头中给出
- 303:浏览器对于POST响应进行重定向至新的url
- 307:浏览器对于GET的响应重定向至新的url
- 403:资源不可用,服务器理解客户的请求,但拒绝处理它(没有权限)
- 404:找不到该页面
- 500:服务器内部错误
- 503:服务器由于维护或者负载过重未能应答,在响应中可能会携带Retry-After响应头,有可能是因为爬虫频繁访问,使服务器忽视爬虫的请求,最终返回503响应状态码
所有的状态码都不可信,一切以是否从抓包得到的响应中获取到数据为准
Requests模块
官网:Requests: HTTP for Humans™ — Requests 2.31.0 documentation
基本介绍
本阶段课程主要学习requests这个http模块,该模块主要用于发送请求获取响应,该模块有很多的替代模块,比如说urllib模块,但是在工作中用的最多的还是requests模块,requests的代码简洁易懂,相对于臃肿的urllib模块,使用reauests编写的爬虫代码将会更少,而且实现某一功能将会简单。因此建议大家掌握该模块的使用。
知识点:
- 掌握headers参数的使用
- 掌握发送带参数的请求
- 掌握headers中携带cookie
- 掌握cookies参数的使用
- 掌握cookieJar的转换方法
- 掌握超时参数timeout的使用
- 掌握代理ip参数proxies的使用
- 掌握使用verify参数忽略CA证书
- 掌握requests模块发送post请求
- 掌握利用requestssession进行状态保持
requests模块:python中原生的一款基于网络请求的模块,功能非常强大,简单便捷,效率极高。
作用:模拟浏览器发送请求。
如何使用:(requests模块的编码流程):
- 指定url
- 发起请求
- 获取响应数据
- 持久化存储
环境安装:pip install requests
1 | import requests |
响应对象
实战:获取sogou首页的数据
1 | import requests |
1.response.text是requests模块按照charset模块推测出的编码字符集进行解码的结果
Content of the response, in unicode.
If Response.encoding is None, encoding will be guessed usingchardet.
The encoding of the response content is determined based solely on HTTP headers, following RFC 2616 to the letter. If you can take advantage of
non-HTTP knowledge to make a better guess at the encoding, you should setr.encodingappropriately before accessing this property
2.网络传输的字符串都是bytes类型的,所以response.text = response.content.decode(推测出的编码字符集')
3.我们可以在网页源码中搜索charset,尝试参考该编码字符集,注意存在不准确的情况

response.text和response.content的区别
response.text
类型:str
解码类型:requests模块自动根据HTTP头部对响应的编码作出有根据的推测,推测的文本编码

response.content
- 类型:bytes
- 解码类型:没有指定
response.content.decode()解决中文乱码
默认是utf-8
可以设置其他解码格式,如response.content.decode("GBK")
常见的字符编码集合:
- utf-8
- gbk
- gb2312
- ascii
- iso-8859-1
解码百度首页
1 | import requests |
响应对象编码的兼容性处理
在Python的爬虫中,使用requests库发送请求获取响应后,处理响应对象的编码格式是很重要的,因为网页内容可能使用不同的编码方式表示(如UTF-8、GBK等)。为了处理这种情况,你可以按照以下步骤进行兼容性处理:
- 导入必要的库:
1 | import requests |
- 发送请求并获取响应:
1 | url = 'http://example.com' # 将此处替换为你要请求的URL |
- 处理响应的编码格式:
1 | if response is not None: |
在这个过程中,首先从响应的Content-Type头部中获取编码信息,然后使用获取到的编码对响应内容进行解码。如果解码失败,就使用默认的Unicode解码。这样能够兼容处理大多数网页的编码情况。
响应对象的其他属性和方法
response.url
- 响应的url;有时候响应的url和请求的url并不一致
response.status_code
- 响应状态码
response.request.headers
- 响应对应的请求头
response.headers
- 响应头
response.request._cookies
- 响应对应请求的
cookie;返回cookieJar类型
response.cookies
- 响应的
cookie(经过了set-cookie动作);返回cookieJar类型
response.json()
- 自动将json字符串类型的响应内容转换为python对象(dictor list)
1 | import requests |
请求对象
headers请求头
对比浏览器上,百度的首页和代码中的百度首页,源码有什么不同
- 查看网页源码的方式:右键 - 查看网页源代码,或右键 - 检查
对比对应url的响应内容和代码中的百度首页源码,有什么不同
- 查看对应url的响应内容的方法
- 右键 - 检查
- 点击
Network - 刷新页面
- 查看
Name一栏下和浏览器地址相同的url的Response
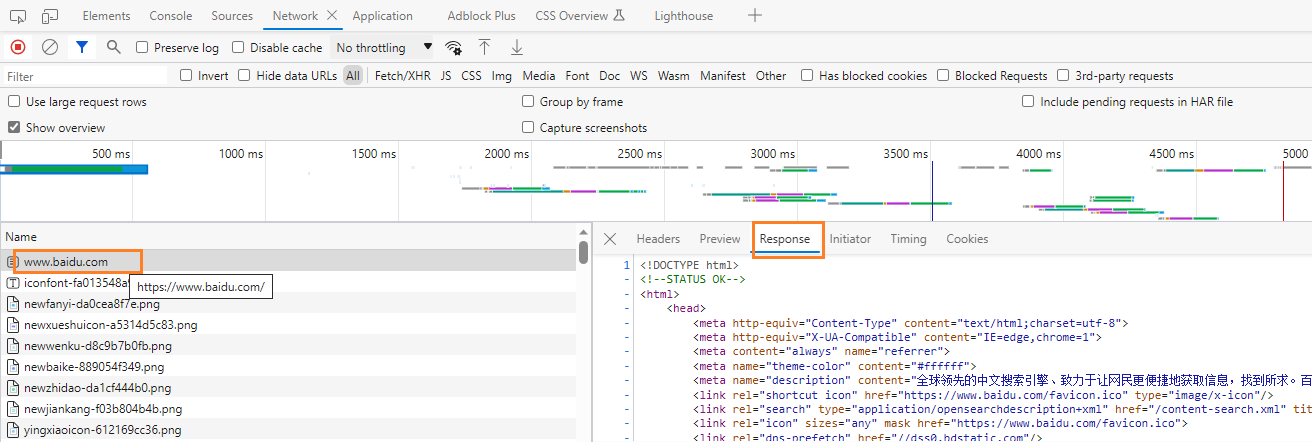
- 查看对应url的响应内容的方法
代码中的百度首页的源码非常少,为什么?
需要我们带上请求头信息
回顾爬虫的概念,模拟浏览器,欺骗服务器,获取和浏览器一致的内容
请求头中有很多字段,其中
User-Agent字段必不可少,表示客户端的操作系统以及浏览器的信息
headers请求头
requests.get(url, headers = headers)
headers参数接收字典形式的请求头- 请求头字段名作为
key,字段对应的值作为value
1 | # 从浏览器中复制User-Agent,构造headers字典 |
携带参数
直接对含有参数的url发起请求
1 | import requests |
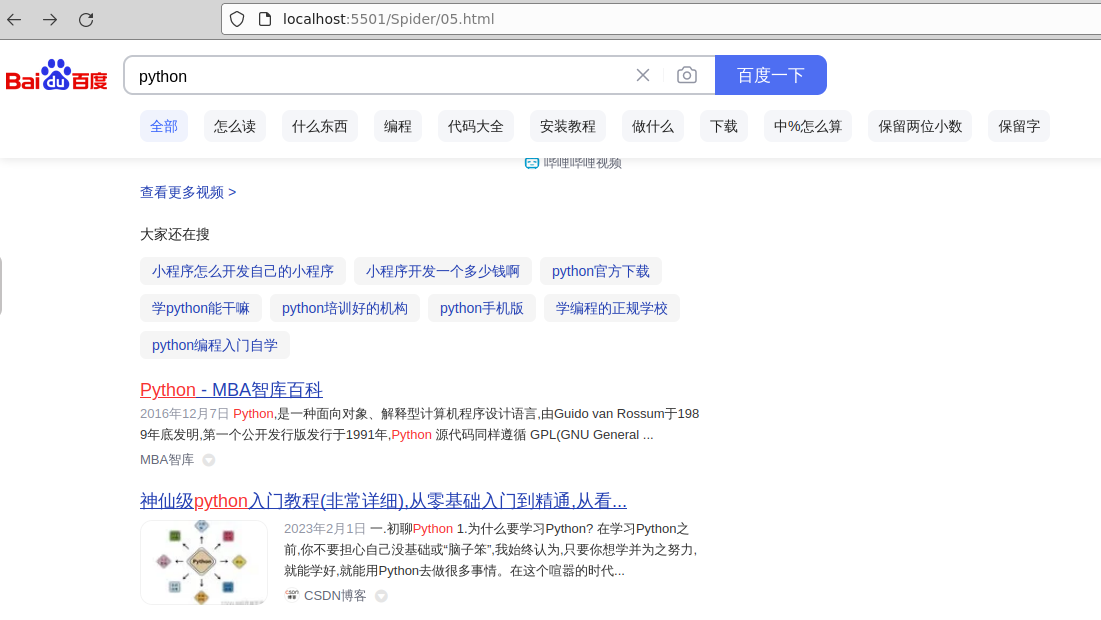
通过params携带参数字典
我们在使用百度搜索的时候经常发现url地址中会有一个
?,那么该问号后边的就是请求参数,又叫做查询字符串
直接对含有参数的url发起请求
1
2
3
4
5
6
7
8
9import requests
url = 'https://www.baidu.com/s?wd=python'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.1823.51"
}
response_content = requests.get(url, headers=headers).content.decode()
with open('05.html', 'w', encoding='utf-8') as fw:
fw.write(response_content)通过
params携带参数字典- 构建请求参数字典
- 向接口发送请求时带上参数字典,参数字典设置
params
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18import requests
# url = 'https://www.baidu.com/s?wd=python'
url = 'https://www.sogou.com/web'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.1823.51"
}
kw = {
'query': 'python'
}
response = requests.get(url, headers=headers, params=kw)
print(response.request.url) # https://www.sogou.com/web?query=python
response_content = response.content.decode()
with open('05_02.html', 'w', encoding='utf-8') as fw:
fw.write(response_content)
携带Cookie
headers中携带Cookie
网站经常利用请求头中的Cookie字段来做用户访问状态的保持,那么我们可以在headers参数中添加Cookie,模拟普通用户的请求。
我们以github登陆为例:
1.打开浏览器,右键-检查,点击Network,勾选Preservelog
2.访问qithub登陆的url地址:https://github.com/login
3.输入账号密码点击登陆后,访问一个需要登陆后才能获取正确内容的url,比如点击右上角的Your profile<访问https://github.com/USER NAME
4.确定url之后,再确定发送该请求所需要的请求头信息中的User-Agent和Cookie
直接请求:https://www.baidu.com/my/dynamic_num,提示未登录
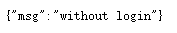
获取请求头:请求头可以先在浏览器上登陆,然后手动复制一下
携带请求头发送请求:
1 | import requests |
使用专门的cookie参数
cookie参数的形式:字典cookies = {"cookieName": "cookieValue"}- 该字典对应请求头中的
Cookie字符串,以分号、空格分割每一对字典键值对 - 等号左边对应
cookie的key,等号右边对应cookie的对应的键值
- 该字典对应请求头中的
cookie参数的使用方法response = requests.get(url, cookies)将
cookie字符串,转换为cookie参数字典cookie_dict = {cookie.split('=')[0]: cookie.split('=')[-1] for cookie in cookie_str.split(';')}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20import requests
# url = 'https://www.baidu.com/s?wd=python'
url = 'https://www.baidu.com/my/dynamic_num'
cookie_str = "PSTM=1637026828; BIDUPSID=7876061D0B15D80852EF5244A72C2D4A; __yjs_duid=1_476ec926978bc7c0f43ffd9a3ab3c1e31637061031193; BDSFRCVID=bouOJeCmHRSv95cfyxqXUwi3neKK0gOTHllnCFSCljnL_w0VJeC6EG0Ptf8g0KubFTPRogKK0gOTH6KF_2uxOjjg8UtVJeC6EG0Ptf8g0M5; H_BDCLCKID_SF=tJkD_I_hJKt3j45zK5L_jj_bMfQE54FXKK_s3J7aBhcqEn6S0lb-ejLSblrOblvPbKKeWJ5cWKJJ8UbSh-v_LUK9LUvB2f7dbbRpaJ5nJq5nhMJmb67JDMP0-4jnQpjy523ion3vQpP-OpQ3DRoWXPIqbN7P-p5Z5mAqKl0MLPbtbb0xXj_0-nDSHH_fJjtO3f; H_WISE_SIDS=219946_234925_234020_131861_219561_216852_213363_214800_219943_213028_204916_230288_242158_110085_227870_236307_243706_243881_244730_240590_244955_245411_245701_245599_247130_234207_247974_248175_248668_248779_247629_249014_249123_247585_107311_249811_232281_249922_249909_249982_250180_250122_250617_247146_250738_250888_251068_249343_251263_247509_250534_251621_251133_251415_251836_245217_252007_252122_252261_247671_248079_250759_252601_252639_252558_251964_249892_245919_247460_252580_252944_252993_253044_252786_247450_234295_251580_253065_248644_253465_253481_252353_253427_253566_248437_253705_253682_252208_253731_253516_250091_253952_8000051_8000099_8000111_8000132_8000139_8000150_8000164_8000165_8000168_8000179_8000203; BD_UPN=12314753; H_WISE_SIDS_BFESS=219946_234925_234020_131861_219561_216852_213363_214800_219943_213028_204916_230288_242158_110085_227870_236307_243706_243881_244730_240590_244955_245411_245701_245599_247130_234207_247974_248175_248668_248779_247629_249014_249123_247585_107311_249811_232281_249922_249909_249982_250180_250122_250617_247146_250738_250888_251068_249343_251263_247509_250534_251621_251133_251415_251836_245217_252007_252122_252261_247671_248079_250759_252601_252639_252558_251964_249892_245919_247460_252580_252944_252993_253044_252786_247450_234295_251580_253065_248644_253465_253481_252353_253427_253566_248437_253705_253682_252208_253731_253516_250091_253952_8000051_8000099_8000111_8000132_8000139_8000150_8000164_8000165_8000168_8000179_8000203; BAIDUID=07B4602566E01B53F52BD76F6F5C9668:FG=1; MCITY=-315%3A; H_PS_PSSID=38515_36546_38686_38794_38907_38792_38832_38808_38838_38637_26350_22157; ispeed_lsm=10; BAIDUID_BFESS=07B4602566E01B53F52BD76F6F5C9668:FG=1; BDSFRCVID_BFESS=bouOJeCmHRSv95cfyxqXUwi3neKK0gOTHllnCFSCljnL_w0VJeC6EG0Ptf8g0KubFTPRogKK0gOTH6KF_2uxOjjg8UtVJeC6EG0Ptf8g0M5; H_BDCLCKID_SF_BFESS=tJkD_I_hJKt3j45zK5L_jj_bMfQE54FXKK_s3J7aBhcqEn6S0lb-ejLSblrOblvPbKKeWJ5cWKJJ8UbSh-v_LUK9LUvB2f7dbbRpaJ5nJq5nhMJmb67JDMP0-4jnQpjy523ion3vQpP-OpQ3DRoWXPIqbN7P-p5Z5mAqKl0MLPbtbb0xXj_0-nDSHH_fJjtO3f; BD_HOME=1; ZFY=SLHAPcaUA4Pq:BlGqfQhGdLx3KsZyaB0P1V6irWENyJ8:C; BA_HECTOR=80ah8184ahag00a4802k210l1i9f5cr1o; BDUSS=RFMzRtRFlmSTFtYmlJQTliS2ZTanRoOTI0Y1dkMmJSbWRmWE9QeGhCb2NJNzlrSUFBQUFBJCQAAAAAAAAAAAEAAAAkXvml5fvPozIzNAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAByWl2QclpdkTj; BDUSS_BFESS=RFMzRtRFlmSTFtYmlJQTliS2ZTanRoOTI0Y1dkMmJSbWRmWE9QeGhCb2NJNzlrSUFBQUFBJCQAAAAAAAAAAAEAAAAkXvml5fvPozIzNAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAByWl2QclpdkTj; BDORZ=FAE1F8CFA4E8841CC28A015FEAEE495D; Hmery-Time=3425267732; ab_sr=1.0.1_ZDc4Y2U2M2M3NmIwMTg2ODRmY2EzM2U2ZGUxNmRkYjVhNTFjNTJiZWRlMzBhMjA1YTNhZmQyMGQ5OTdmYzhmNGVjMjQ3MTNjYzA0MjVmODdlYzliZDY2NTk4M2U4NjU5MWUxYjcwZGFjMWY0YzJiZTNhNzMxYzM4MTRjZDNjZjg4NTQ2ZmNiYzE5NzcyMzJlMjhhNzk2YTc3ZWQyN2U5OA=="
cookies = {cookie.split('=')[0]: cookie.split(
'=')[-1] for cookie in cookie_str.split(';')}
print(cookies)
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.1823.51"
}
response = requests.get(url, headers=headers, cookies=cookies)
response_content = response.content.decode()
with open('06_02.json', 'w', encoding='utf-8') as fw:
fw.write(response_content)这种切分字符串的方式,
cookieValue两端可能更还会包括空格(留着也可以正常发请求)注意:
cookie一般是有过期时间的,一旦过期,需要重新获取1
2# cookie过期重新获取
# @Todo
cookeJar对象转化
使用request获取到的Response对象,具有的
cookie属性是一个cookieJar类型,其包含了服务器设置的cookie我们需要将其转换成
python中的字典
转化方法
cookies_dict = requests.utils.dict_from_cookiejar(response.cookies)其中,
response.cookies就是cookieJar对象:<RequestsCookieJar[]>,上述方法返回python类型的cookie字典1
2
3
4
5
6
7
8
9
10
11
12
13
14import requests
url = 'https://www.baidu.com'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.1823.51"
}
response = requests.get(url, headers=headers)
print(response.cookies)
# <RequestsCookieJar[<Cookie BAIDUID=DBED0AE90FAB0113AC2E2D59DE66B143:FG=1 for .baidu.com/>, <Cookie BIDUPSID=DBED0AE90FAB0113A4FD62F3C2763A23 for .baidu.com/>, <Cookie H_PS_PSSID=38515_36553_38687_38880_38796_38903_38844_38831_38918_38808_38825_38836_26350 for .baidu.com/>, <Cookie PSTM=1687663300 for .baidu.com/>, <Cookie BDSVRTM=0 for www.baidu.com/>, <Cookie BD_HOME=1 for www.baidu.com/>]>
cookies_dict = requests.utils.dict_from_cookiejar(response.cookies)
print(cookies_dict)
# {'BAIDUID': 'DBED0AE90FAB0113AC2E2D59DE66B143:FG=1', 'BIDUPSID': 'DBED0AE90FAB0113A4FD62F3C2763A23', 'H_PS_PSSID': '38515_36553_38687_38880_38796_38903_38844_38831_38918_38808_38825_38836_26350', 'PSTM': '1687663300', 'BDSVRTM': '0', 'BD_HOME': '1'}也可以将一个参数字典,转换成
cookieJar对象。但是会丢失域名1
2
3
4cookie_jar = requests.utils.cookiejar_from_dict(cookies_dict)
print(cookie_jar)
# <RequestsCookieJar[<Cookie BAIDUID=B769B49A969318E68D1A355D558EEE3B:FG=1 for />, <Cookie BAIDUID_BFESS=B769B49A969318E6ABAA167F9536E529:FG=1 for />, <Cookie BDSVRTM=0 for />, <Cookie BD_HOME=1 for />, <Cookie BIDUPSID=B769B49A969318E6ABAA167F9536E529 for />, <Cookie H_PS_PSSID=38516_36555_38687_38881_38903_38792_38844_38831_38811_38826_38839_38639_26350 for />, <Cookie PSTM=1687664041 for />]>
超时参数
一个请求等了很久,可能依然没有结果
可以强制在特定的时间返回结果,否则就报错
超时参数
timeout的使用方法response = requests.get(url, timeout = 3)单位是秒
timeout =3表示,发送请求后,3秒内返回响应,否则抛出异常1
2
3
4
5
6
7
8
9import requests
url = 'https://www.google.com'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.1823.51"
}
response = requests.get(url, headers=headers, timeout=3)
# requests.exceptions.ConnectTimeout: HTTPSConnectionPool(host='www.google.com', port=443): Max retries exceeded with url: / (Caused by ConnectTimeoutError(<urllib3.connection.HTTPSConnection object at 0x7f9aacde3220>, 'Connection to www.google.com timed out. (connect timeout=3)'))
verify参数
使用verify参数忽略CA证书
如:https://sam.huat.edu.cn:8443/selfservice/
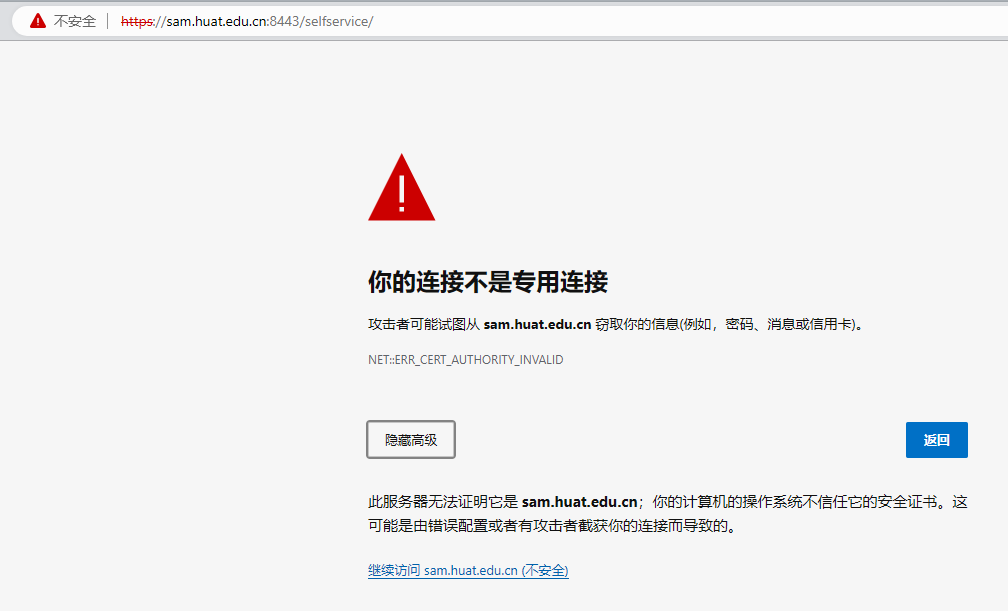
原因:该网站的CA证书没有经过【受信任的根证书颁发机构】的认证
运行代码查看向不安全的链接发起请求的效果
1
2
3
4
5
6
7
8
9
10
11import requests
url = 'https://sam.huat.edu.cn:8443/selfservice/'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.1823.51"
}
response = requests.get(url, headers=headers)
print(response)
# Error(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: EE certificate key too weak (_ssl.c:1131)')))解决方案:为了在代码中能够正常的请求,我们使用
verify = False参数,此时requests模块发送请求将不做CA证书的验证1
2
3
4
5
6
7
8
9
10
11
12import requests
url = 'https://sam.huat.edu.cn:8443/selfservice/'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.1823.51"
}
response = requests.get(url, headers=headers, verify=False)
print(response)
# 会报一个警告,但不影响
# /app/env/env_python_data/lib/python3.8/site-packages/urllib3/connectionpool.py:1095: InsecureRequestWarning: Unverified HTTPS request is being made to host 'sam.huat.edu.cn'. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/latest/advanced-usage.html#tls-warnings
发送post请求
思考:哪些地方我们会用到POST请求
- 登陆注册(POST比GET更安全,url地址中不会暴露用户的帐号密码等信息)
- 需要传输大文本内容的时候(POST请求对数据长度没有要求)
发送
post请求的方法1
response = requests.post(url, data)
data参数接收一个字典,其他的参数与get请求的参数保持一致1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34import requests
import json
import sys
# @TODO 1.自动更新params参数的中的sign。2.支持不同语言的互相翻译
class King(object):
def __init__(self, word):
self.word = word
self.url = 'https://ifanyi.iciba.com/index.php'
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.1823.51"
}
# sign会过期
self.params = {
'c': 'trans', 'm': 'fy', 'client': '6', 'auth_user': 'key_web_fanyi', 'sign': 'd5dc97e74b159da2'
}
self.data = {'from': 'zh', 'to': 'en', 'q': self.word}
def get_data(self):
response = requests.post(url=self.url, headers=self.headers, params=self.params, data = self.data)
return response.content.decode()
def parse_data(self, data):
try:
dict_data = json.loads(data)
print(dict_data['content']['out'])
except:
print('error')
def run(self):
data_response = self.get_data()
print(data_response)
self.parse_data(data_response)
if __name__ == '__main__':
word = sys.argv[1]
king = King(word)
king.run()
post数据来源
确定好url后,难点在于怎么构建
data
固定值
- 固定参数
- 抓包比较不变值
输入值
- 与自己输入的数据有关
- 抓包比较自身变化值
预设值(传输值)
服务器返回的其他文件、接口或本地客户端
js生成提供,如sign、token等参数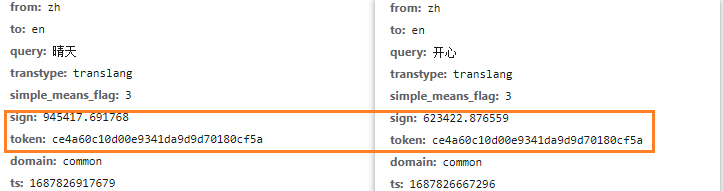
预设值存储在静态文件中
如:百度翻译。通过搜索发现,
token值直接写在了首页静态文件中: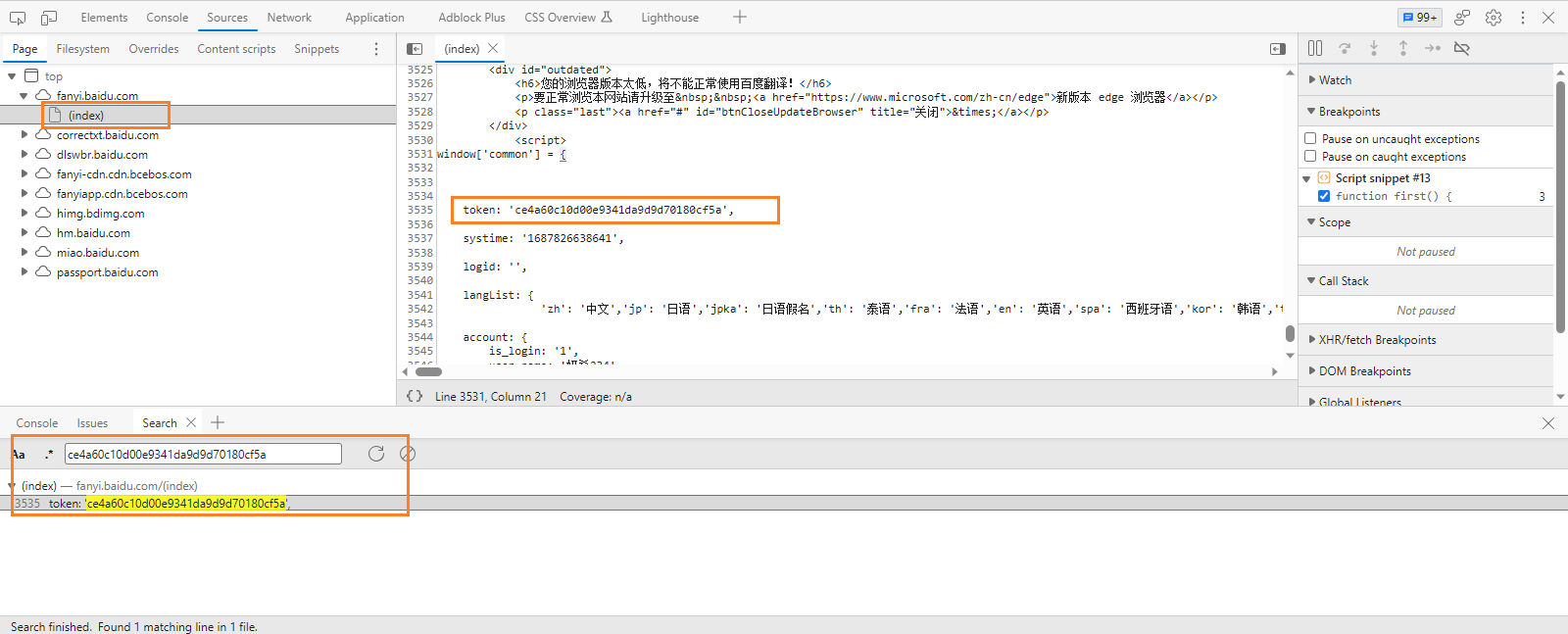
流程如下:先请求
index.html首页静态文件,其中的js代码在window全局对象挂载了common对象,后续发送请求时,去window上拿common对象中的值。而从爬虫的角度,只要先获取首页文件,然后提取出token即可。预设值,需要先对其他地址发送一个(或多个)请求,才能构建
data预设值,是在客户端中通过
js代码生成的。
状态保持
requests模块中的Session类,能够自动处理发送请求获取响应过程中,产生的cookie,进而达到状态保持的目的
session实例在请求了一个网站后,对方服务器设置在本地的cookie会保存在在session实例中,下一次再使用session请求对方服务器的时候,会带上前一次的cookie
作用:自动处理
cookie,即下一次请求会带上前一次的cookie应用场景:处理连续的多次请求过程中,产生的
cookie基本使用:
1
2
3
4
5import requests
session = requests.Session()
response = session.get(url, headers=headers, params=kw)
response = session.post(url, headers=headers, data)使用
request.session登陆github,并获取需要登陆后才能访问的页面1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71# -*- encoding: utf-8 -*-
'''
@File : 11_requests_session登陆github.py
@Time : 2023/06/29 09:04:48
@Version : 1.0
@Desc :
# 创建session对象
# 设置headers
# url1-获取token
# 发送请求获取响应
# 正则提取
# url2-登陆
# 构建表单数据
# 发送请求登陆
# url3-验证
'''
# import lib here
import requests
import re
class Github():
def __init__(self):
self.session = requests.Session()
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.1823.51"
}
self.token = ''
self.data = {
'commit': 'Sign in',
'authenticity_token': self.token,
'login': 'mindcons',
'password': 'gi@tMid#123',
'webauthn-conditional': 'undefined',
'javascript-support': 'true',
'webauthn-support': 'supported',
'webauthn-iuvpaa-support': 'unsupported',
'return_to': 'https://github.com/login',
'timestamp': '1688020307382',
'timestamp_secret': '99b817e7a8c3623cb2a980ab4815ca4ca1689ad6bce9d71b50bd2420a5327d88'
}
def get_token(self, url1):
response = self.session.get(
url1, headers=self.headers).content.decode()
self.token = re.findall(
'name="authenticity_token" value="(.*?)"', response)
def login(self, url2):
response = self.session.post(
url2, headers=self.headers, data=self.data)
def login_check(self, url3):
response = self.session.get(url3)
with open('11.html', 'w', encoding='utf-8') as fw:
fw.write(response.text)
if __name__ == '__main__':
ins = Github()
url1 = 'https://github.com/login'
url2 = 'https://github.com/session'
url3 = 'https://github.com/mindcons'
ins.get_token(url1)
print(ins.token)
ins.login(url2)
ins.login_check(url3)
cookie过期处理办法:在这个示例中,首先创建了一个
requests.Session对象,并使用session.cookies.set方法设置初始的Cookie(如果需要的话)。然后,使用session.get方法发送HTTP请求,获取响应。如果响应返回状态码为200,表示请求成功,我们可以检查响应头部中的
Set-Cookie字段。如果存在Set-Cookie字段,表示服务器返回了新的Cookie值。我们可以通过访问response.headers['Set-Cookie']来获取新的Cookie值。接下来,我们使用
session.cookies.set方法来更新Session对象中的Cookie值,将旧的Cookie替换为新的Cookie。最后,我们可以使用更新后的Cookie值发送带有新Cookie的请求,例如
session.get('https://example.com')。通过这种方式,我们可以处理过期的Cookie,并在Session对象中更新它们,以便后续请求中使用最新的Cookie。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24import requests
# 创建Session对象
session = requests.Session()
# 设置初始的Cookie(可选)
session.cookies.set('cookie_name', 'cookie_value')
# 发送HTTP请求
response = session.get('https://example.com')
# 处理过期的Cookie
if response.status_code == 200:
# 检查响应中的Set-Cookie头部
if 'Set-Cookie' in response.headers:
# 获取新的Cookie值
new_cookie = response.headers['Set-Cookie']
# 更新Session中的Cookie
session.cookies.set('cookie_name', new_cookie)
# 发送带有更新后的Cookie的请求
new_response = session.get('https://example.com')
模拟登陆实现流程梳理
爬取基于某些用户的用户信息
需求:模拟登录
- 点击登录之后,会发起一个post请求
- post请求中会携带登录之前录入的相关的登录信息(用户名、密码、验证码…)
- 验证码:每次请求都会变化
模拟登陆
1 | def gsw(): |
模拟登陆cookie操作
需求:爬取当前用户的相关的用户信息(个人主页中显示的信息)
http/https协议特性:无状态
没有请求到对应页面数据的原因:
- 发起的第二次基于个人主页页面请求的时候,服务器端并不知道该次请求时基于登录状态下的请求。
cookie:用来让服务器端记录客户端的相关状态
- 手动处理:通过抓包工具获取cookie的值,将该值封装到headers中(不建议)
- 自动处理:
- cookie的值来源是哪里?
- 模拟登录post请求后,由服务器端创建
- session会话对象:
- 作用:
- 1.可以进行请求的发送
- 如果请求过程中产生了cookie,则该cookie会被自动存储在该session对象中
- 作用:
- 创建一个session对象:
session = requests.Session()
- 使用session对象进行模拟登录post请求的发送(cookie就会被存储在session对象中)
- session对象对个人主页的get请求进行发送(携带了cookie)
- cookie的值来源是哪里?
Requests巩固
深入案例介绍
- 爬取搜狗指定词条,对应的搜索结果页面(简易网页采集器)。
- 破解百度翻译。
- 爬取豆瓣电影分类排行榜中的电影详情数据。
- 爬取肯德基餐厅查询中,指定地点的餐厅数。
- 爬取国家药品监督管理总局基于中华人民共和国化妆品生产许可证相关数据。
简易网页采集器
- UA检测
- UA伪装
1 | import requests |
百度翻译
- post请求(携带了参数)
- 响应是一组Json数据
resposne.json()直接返回的是obj
1 | import requests |
豆瓣电影
1 | import requests |
备注:会被限制ip,response返回的是403
作业
肯德基餐厅
观测地址栏的url有没有发生变化,如果没有发生变化,但是数据发生了更新,表示发送了ajax请求。
1 | import requests |
备注:这里请求的url,不要去掉后面的参数
快速生成一个爬虫demo
然后打开:Convert curl commands to code (curlconverter.com)
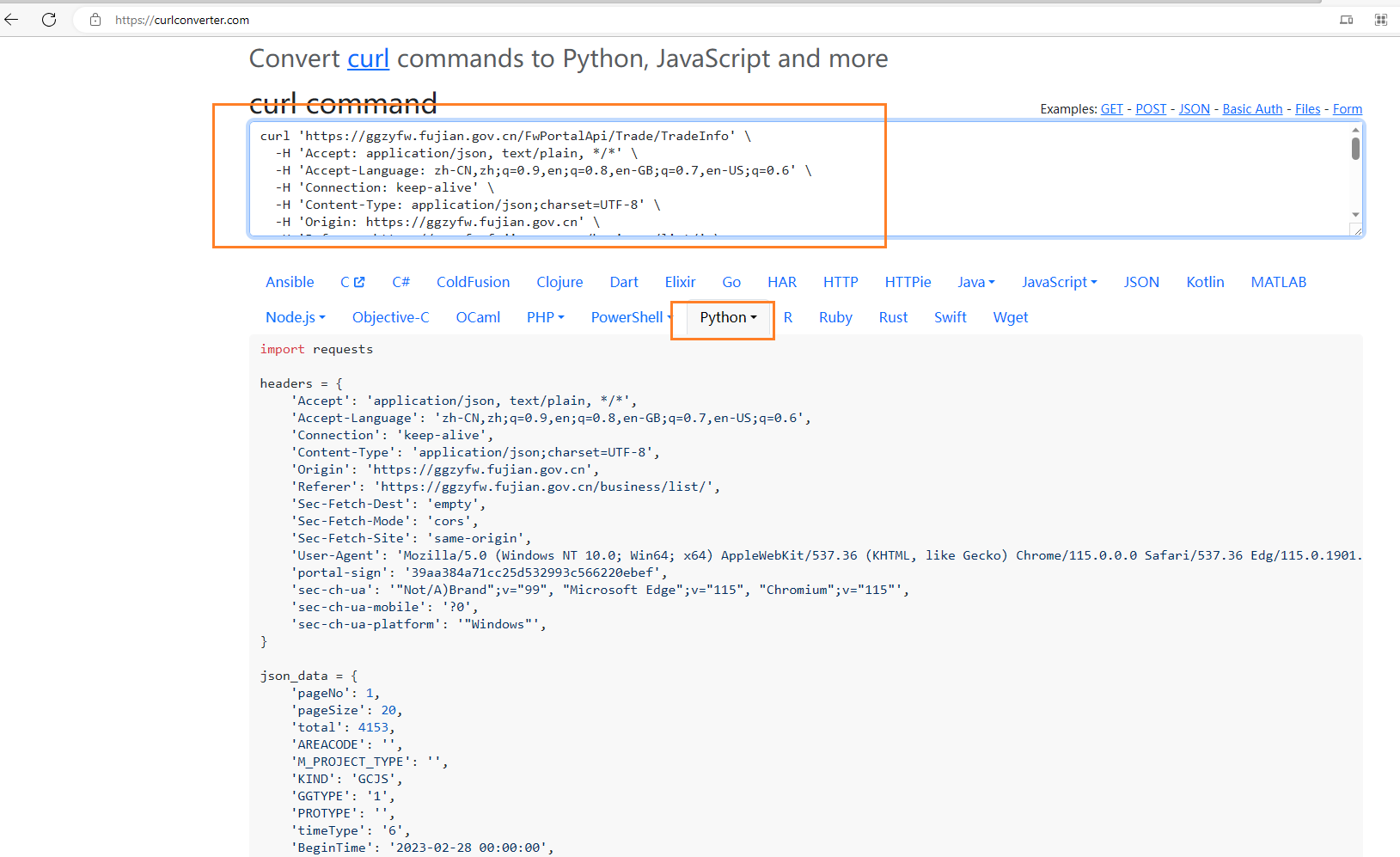
注意事项
1.定位数据接口,判断是动态数据还是静态数据
2.区分他们的请求方式
get,对应参数post,对应data
3.检索headers、data、params、数据以及是否存在加密内容
4.构建合理的headers
- 一般
Referer和User-Agent是必填的
5.发送请求
综合练习
药监总局01
- url的域名都是一样的,只有携带的参数(id)不一样
- id值可以从首页对应的ajax请求到的json串中获取
settings.py
1 | START_URL = { |
utils.py
1 | import json |
spider_task.py
1 | import requests |
数据解析
聚焦爬虫:爬取页面中指定的页面内容
编码流程:
- 指定url
- 发起请求
- 获取响应数据
- 数据解析
- 持久化存储
数据解析分类:
- 正则
- bs4
- xpath
数据解析原理概述:
- 解析的局部的文本内容都会在标签之间或者标签对应的属性中进行存储
- 进行指定标签的定位
- 标签或者标签对应的属性中存储的数据值进行提取(解析)
响应数据的类型:
response.text,处理字符串类型的响应数据response.content,处理二进制类型的响应数据response.json(),处理Json类型(对象类型)的响应数据
响应内容的分类
在发送请求获取响应之后,可能存在多种不同的响应内容,而且很多时候,我们只需要响应内容中的一部分数据
- 结构化响应内容
json字符串- 可以使用
re(正则)、json、jsonpath等模块提取特定数据
- 可以使用
xml字符串- 可以使用
re(正则)、lxml(xpath语法)等模块来提取特定数据
- 可以使用
- 非结构化响应内容
html- 可以使用
re(正则)、lxml(xpath语法)、beautifulsoup(xpath、正则、css选择器)、pyquery(css选择器)等模块来提取特定数据
- 可以使用
jsonpath模块
如果有一个多层嵌套的复杂字典,想要根据
key和下标来批量提取value,这是比较困难的。
jsonpath模块就能解决这个痛点,jsonpath可以按照key对python字典进行批量数据提取。接下来我们学习
jsonpath模块
1 | pip install jsonpath |
1 | from jsonpath import jsonpath |
jsonpath语法规则
常用语法:
$...
| JsonPath | 描述 |
|---|---|
| $ | 根节点 |
| @ | 现行节点 |
| . or [] | 取子节点 |
| n/a | 取父节点,JsonPath未支持 |
| .. | 不管位置,选择所有符合条件的条件 |
| * | 匹配所有元素节点 |
| n/a | 根据属性访问,Json不支持,因为Json是Key-Value递归结构,不需要属性访问 |
| [] | 迭代器标示(可以在里面做简单的迭代操作,如数组下标,根据内容选值等) |
| [,] | 支持迭代器中做多选 |
| ?() | 支持过滤操作 |
| () | 支持表达式计算 |
| n/a | 分组,JsonPath不支持 |
json样例
1 | from jsonpath import jsonpath |
| JsonPath | Result |
|---|---|
$.store.book[*].author |
store中的所有的book作者 |
$..author |
所有的作者 |
$.store.* |
store下的所有元素 |
$.store..price |
store中的所有的内容的价格 |
$..book[2] |
第三本书 |
| `$..book[(@.length-1)] | $..book[-1:]` |
| `$..book[0,1] | $..book[:2]` |
$..book[?(@.isbn)] |
获取有isbn的所有数 |
$..book[?(@.price<10)] |
获取价格大于10的所有的书 |
$..* |
获取所有的数据 |
jsonpath案例
1 | # 获取网络接口数据,json格式 |
lxml模块和xpath语法
lxml模块和xpath语法的关系
对
html或xml格式的文本进行内容提取,就需要lxml模块和xpath语法
lxml模块可以利用xpath规则,来定位html\xml文档中的特定元素,以及获取节点信息(文本内容、属性值)xpath(XML Path Language)是一门在html\xml文档中查找信息的语言,可用来在html\xml文档中对元素和属性进行遍历- 提取
html\xml中的数据需要lxml模块和xpath语法配合使用
xpath helper
自行搜索安装插件
基础语法:
| 表达式 | 描述 |
|---|---|
nodename |
标签名,选中该元素 |
| / | 从根节点选取,或者是元素和元素的过渡 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置 |
| . | 选取当前节点 |
| .. | 选取当前节点的父节点 |
| @ | 选取属性 |
| text() | 选取文本 |
- 选中所有的
h2下的文本://h2/text() - 获取所有的
a标签的href://a/@href - 获取
html下的head下的link标签的href:/html/head/link/@href
特殊节点语法:
| 路径表达式 | 结果 |
|---|---|
//title[@lang="eng"] |
选择lang属性值为eng的所有title元素 |
/bookstore/book[1] |
选取属于bookstore子元素的第一个book元素 |
/bookstore/book[last()] |
选取属于bookstore子元素的最后一个book元素 |
/bookstore/book[last()-1] |
选取属于bookstore子元素的到数第二个book元素 |
/bookstore/book[position()>1] |
选取bookstore下面的book元素,从第二个开始选择 |
//book/title[text()='Harry Potter'] |
选取所有book下的title元素,仅仅选择文本为Harry Potter的title元素 |
/bookstore/book[price>35.00]/title |
选取bookstore元素中的book元素的所有title元素,且其中的price元素的值须大于35000 |
通配语法:
| 通配符 | 描述 |
|---|---|
* |
匹配任何元素节点 |
@* |
匹配任何属性节点 |
node() |
匹配任何类型的节点 |
xpath解析:最常用且最便捷高效的一种解析方法,通用性。
xpath解析原理
- 1.实例化一个
etree对象,且需要将被解析的页面源码数据加载到该对象中 - 2.调用
etree对象中的xpath方法,结合着xpath表达式是实现标签的定位和内容的捕获
环境的安装
pip install lxml
如何实例化一个etree对象
1.将本地的html文档中的源码数据加载到etree对象中
etree.parse(filepath)2.可以将从互联网上获取到的源码数据加载到该对象中
etree.HTML('page_text')3.
xpath('xpath表达式')
xpath表达式
/表示的是从根节点开始定位。表示的是一个层级//表示的是多个层级。可以表示从任意位置开始定位- 属性定位:
//div[@class="song] - 索引定位:
//div[@class="song"]/p[3],索引是从1开始的 - 获取属性:
//img/@href
xpath中,多个选择语句,可以用|符号连接
etree.HTML()会自动的将缺失标签补全
etree.tostring()可以将Element对象再转换回html字符串
更多语法请查阅:XPath 语法 (w3school.com.cn)
提取html内容
安装lxml
1 | pip install lxml |
1 | # 导入lxml模块中的etree库 |
1 | # eree.tostring 将Element对象转换成字符串 |
xpath实战
基本流程
爬取百度贴吧
1 | import requests |
58二手房
1 | def ershoufang(): |
4k图片
解析出的字段为乱码解决方案
1 | # 1 |
1 |
|
全国城市名称
图片数据爬取
单张图片数据爬取
spider_task.py
1 | import requests |
utils_storage.py
1 | # 二进制类型响应对象的本地存储 |
正则模块
单页面的多张图片爬取
1 | import requests |
多页面,多图片爬取
- 设置url请求的通用模板
1 | import requests |
bs4模块
bs4解析概述
bs4只可以用在python中
数据解析的原理
- 1.标签定位
- 2.提取标签、标签属性中存储数据
bs4数据解析的原理:
- 1.实例化一个BeautifulSoup对象,并且将页面元数据加载到该对象中
- 2.通过调用BeautifulSoup对象中的相关的属性或者方法进行标签定位和数据提取
环境安装
pip install bs4pip install lxml
如何实例化BeautifulSoup
导包:
from bs4 import BeautifulSoup对象的实例化
- 1.将本地的html加载到BeautifulSoup对象中
1
# 将本地的html文档中的数据加载到该对象中with open('aa.html','r',encoding='utf-8') as fr: soup = BeautifulSoup(fr,'lxml')
2.将互联网上获取的页面源码加载到该对象中
1
page_text = response.textsoup = BeautifulSoup(page_text,'lxml')
bs4解析具体使用讲解
- 提供的用于数据解析的方法和属性
soup.tagName,等价于soup.find('tagName')- 返回的是html中第一次出现的tagName标签
- 属性定位
soup.find('div',class_='song'),返回类名为song对应的div,记得class要加下划线soup.findAll('tagName'),返回所有的tag标签,返回值为数组
- 标签选择器(和CSS选择器一致),返回的是列表
select('.song'),类选择器select('#song'),id选择器select('a'),标签选择器- 层级选择器
select('.tag > ul > li > a'),单个多层级用>表示select('.tang > ul a),多个层级用空格表示
- 层级选择器中,不支持索引定位
- 获取标签之间的文本数据
soup.a.text/string/get_text()- 区别
text/get_text(),可以获取某一个标签中的所有文本内容string,只可以获取该标签下面直系的文本内容
代理
代理理论讲解
代理:破解封IP这种反爬机制
什么是代理:
- 代理服务器
代理ip:
是一个ip,指向的是一个代理服务器
代理服务器能够帮助我们向目标服务器转发请求
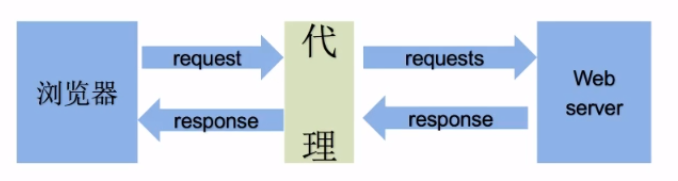
代理的作用:
- 突破自身IP访问的限制
- 隐藏自身真是IP
代理相关的网站:
代理在爬虫中的应用
代理ip的类型:
根据网站所使用的协议不同,需要使用相应协议的代理服务,从代理服务器请求使用的协议可以分为:
- http:应用到http协议对应的url中
- https:应用到https协议对应的url中
代理ip的匿名度:
透明代理(
Transparent Proxy)透明代理虽然可以因此直接“隐藏”你的
IP地址,但是还会是查到你是谁。服务器知道该次请求使用了代理,也知道请求对应的真实ip服务器接收到的请求头如下:
1
2
3REMOTE_ADDR = Proxy IP
HTTP_VIA = Proxy IP
HTTP_X_FORWARDED = Your IP
匿名代理(
Anonymous Proxy)知道使用了代理,不知道真实ip
别人只知道你用了代理,无法知道你是谁,目标服务器接收到的请求头如下:
1
2
3REMOTE_ADDR = Proxy IP
HTTP_VIA = Proxy IP
HTTP_X_FORWARDED = Proxy IP
高匿(
Elite Proxy或High Anonymity Proxy)不知道使用了代理,更不知道真实的
ip高匿代理让别人根本无法发现你是在用代理,所以是最好的选择,目标服务器接收到的请求如下:
1
2
3REMOTE_ADDR = Proxy IP
HTTP_VIA = not determined
HTTP_X_FORWARDED = not determined
代码:
response = requests.get(url=url,headers=headers,proxies={"http":"1.127.0.1:8080})
1 | import requests# 根据协议类型,选择不同的代理 |
正向代理与反向代理
前面提到
proxy参数,指定的代理ip指向的是正向代理服务器,那么相应的,就有反向代理服务器
- 从发送请求的一方的角度,来区分正向或反向代理
- 为浏览器或客户端(发送请求的一方)转发请求的,叫做正向代理
- 浏览器知道最终处理请求的服务器的真实ip地址,例如vpn
- 不为浏览器或客户端(发送请求的一端)转发请求,而是为最终处理请求的服务器转发,叫做反向代理
- 浏览器不知道服务器的真实地址,例如
nginx
- 浏览器不知道服务器的真实地址,例如
proxies代理参数的使用
为了让服务器以为不是同一个客户端在请求,为了防止频繁向同一个域名发送请求被封
ip,所以我们需要使用代理ip
用法:
1
response = requests.get(url, proxies=proxies)
proxies的形式:字典1
2
3
4proxies = {
"http": "http://12.223.43.79:8843",
"https": "https://12.84.235.79:9843"
}如果
proxies字典中包含有多个键值对,发送请求时按照url地址来选择使用相应的代理ip
异步爬虫
异步爬虫概述
在爬虫中使用异步,实现高性能的数据爬取操作
异步爬虫的方式:
- 多线程,多进程:
- 好处:可以为相关阻塞的操作单独开启线程或者进程,阻塞操作就可以异步执行。
- 弊端:无法无限制的开启多线程或者多进程
异步爬虫-多进程&多线程
- 进程池、线程池(适当地使用)
- 可以降低系统对进程和线程创建和销毁的一个频率,从而很好的降低系统的开销。
- 弊端:池中线程的数量是有上限的。
异步爬虫-进程池&线程池
单线程模拟
1 | def get_page(str): print('downloading...') time.sleep(2) print('don=wnloaded successed!',str)name_list= ['a','b','c','d']strat_time = time.time()for i in range(0,len(name_list)): get_page(name_list[i])end_time = time.time()print('%d seconds' % (end_time - strat_time)) |
结果
1 | downloading...donwnloaded successed! adownloading...donwnloaded successed! bdownloading...donwnloaded successed! cdownloading...donwnloaded successed! d8 seconds |
线程池
1 | def get_page(str): print('downloading...') time.sleep(2) print('donwnloaded successed!',str)name_list= ['a','b','c','d']strat_time = time.time()# 实例化一个线程池对象pool = Pool(4)# 将列表的每一个列表元素传递给get_page依次处理pool.map(get_page, name_list)end_time = time.time()print('%d seconds' % (end_time - strat_time))# 关闭线程池pool.close()pool.join() |
结果
1 | downloading...downloading...downloading...downloading...donwnloaded successed! bdonwnloaded successed! adonwnloaded successed! cdonwnloaded successed! d2 seconds |
8.4.异步爬虫-线程池案例应用
https://www.pearvideo.com/category_5
该网站视频的src链接,是放在ajax的相应对象中的,其对应的url有两个参数,其中一个参数是动态加载的,需要用selenium
9.1.协程相关概念
9.1.1.异步编程
为什么要讲?
- 异步非阻塞、asyncio等等概念,或多或少的听说过
- tornado、fastapi、django3.x asgi、aiohttp等框架或者模块中,都在使用异步(提升性能)
如何讲解?
- asyncio模块进行异步编程
- 实战案例
9.1.2.协程
协程不是计算机提供,而是程序员人为创造的
协程(Coroutine),也可以被称为微线程、是一种用户态的上下文切换技术
简而言之,其实就是通过一个线程实现代码块(不同函数之间)相互切换执行
1 | def func1(): print('1') ... print('2n-1') def func2(): print('2') ... print('2n') func1()func2() |
如上两个函数,协程可以让函数中的不同语句交错执行
实现协程的方法:
greenlet,比较早期的模块。yield关键字asyncio装饰器- python3.4引入的
async/await关键字- python3.5引入的
- 目前比较主流
9.1.2.1.greenlet实现协程
安装pip install greenlet
1 | # -*- coding: utf-8 -*-from greenlet import greenletdef func1(): print('1') # 第2步,输出1 gr2.switch() # 第3步,切换到func2函数 print('2') # 第6步,输出2 gr2.switch() # 第7步,切换到func2函数,从上一次执行的位置继续向后执行 def func2(): print('3') # 第4步,输出3 gr1.switch() # 第5步,切换到func1函数,从上一次的位置继续向后执行 print('4') # 第8步,输出4 gr1 = greenlet(func1)gr2 = greenlet(func2)gr1.switch() # 第1步,去执行func1 |
9.1.2.2.yield关键字
1 | # -*- coding: utf-8 -*-def func1(): yield 1 yield from func2() yield 2 def func2(): yield 3 yield 4 f1 = func1()for item in f1: print(item) |
9.1.2.3.asyncio
在python3.4以及之后的版本
1 | # -*- coding: utf-8 -*-import asyncio@asyncio.coroutinedef func1(): print('1') yield from asyncio.sleep(2) # 遇到IO耗时操作,自动切换到task中的其他任务 print('2') @asyncio.coroutinedef func2(): print('3') yield from asyncio.sleep(2) # 遇到IO耗时操作,自动切换到task中的其他任务 print('4')tasks = [ asyncio.ensure_future(func1()), asyncio.ensure_future(func2()) ]loop = asyncio.get_event_loop()loop.run_until_complete(asyncio.wait(tasks)) |
注意:注意IO自动切换
9.1.2.3.async & await关键字
自python3.5及以后的版本
和上面的本质上类似,可以理解为语法糖
1 | # -*- coding: utf-8 -*-import asyncioasync def func1(): print('1') await asyncio.sleep(2) # 遇到IO耗时操作,自动切换到task中的其他任务 print('2') async def func2(): print('3') await asyncio.sleep(2) # 遇到IO耗时操作,自动切换到task中的其他任务 print('4')tasks = [ asyncio.ensure_future(func1()), asyncio.ensure_future(func2()) ]loop = asyncio.get_event_loop()loop.run_until_complete(asyncio.wait(tasks)) |
9.1.3.协程意义
在一个线程中如果遇到IO等待时间,线程不会傻傻等,利用空闲时间再去干点其他事
案例:去下载三站图片(网络IO)
普通方式
1
import requestsheaders ={ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3947.100 Safari/537.36'}def download_images(url): print('正在下载',url) response = requests.get(url=url,headers=headers).content file_name = url.split('/')[-1] with open(file_name,'wb') as fw: fw.write(response) print('下载结束',url)urls = [ "https://pic.netbian.com/uploads/allimg/210812/230003-1628780403b213.jpg", "https://pic.netbian.com/uploads/allimg/210718/001826-16265387066216.jpg", "https://pic.netbian.com/uploads/allimg/210812/225733-16287802533d30.jpg",]for url in urls: download_images(url)
基于协程的异步
1
import aiohttpimport asyncioasync def fetch(session, url): print('发送请求',url) async with session.get(url,verify_ssl=False) as response: content = await response.content.read() filename = url.rsplit('/')[-1] with open(filename,'wb') as fw: fw.write(content)async def main(): async with aiohttp.ClientSession() as session: urls = [ "https://pic.netbian.com/uploads/allimg/210812/230003-1628780403b213.jpg", "https://pic.netbian.com/uploads/allimg/210718/001826-16265387066216.jpg", "https://pic.netbian.com/uploads/allimg/210812/225733-16287802533d30.jpg", ] tasks = [asyncio.create_task(fetch(session,url)) for url in urls] await asyncio.wait(tasks)if __name__=="__main__": asyncio.run(main())
9.1.4.异步编程
9.1.4.1asyncio事件循环
理解为一个死循环,去检测并执行某些代码
1 | # 伪代码任务列表 = [任务1, 任务2, 任务3...]while True: 可执行的任务列表, 已完成的任务列表 = 去任务列表中检查所有的任务,将'可执行'和'已完成'的任务返回 for 就绪任务 in 可执行的任务列表: 在任务列表中移除 已完成的任务 如果 任务列表 中的任务都已完成,则终止循环 |
1 | import asyncio# 生成(获取)一个事件循环loop = asyncio.get_event_loop()# 将任务放到'任务列表'loop.run_until_complete(任务) |
9.1.4.2.快速上手
协程函数:定义函数的时候,加上修饰符async
协程对象:执行协程函数得到的协程对象
1 | async def func(): passresult = func() |
注意:执行协程函数创建爱你协程对象,函数内部代码不会执行
如果想要运行协程函数内部代码,必须要将协程对象交给事件循环来处理
1 | import asyncioasync def func(): print('aa') result = func()# loop = async.get_event_loop()# loop.run_untl_complete(result)asyncio.run(result) # python3.7 |
9.1.4.3.await关键词
await + 可等待对象(协程对象、Future、Task对象),如IO等待
示例一:
1 | import asyncioasync def func(): print('aa') response = await asyncio.sleep(2) # 只有等待结束,有结果了,才会继续向下执行 print('end',response) asyncio.run(func()) |
示例二:
1 | import asyncioasync def others(): print('start') await asyncio.sleep(2) print('end') return '返回值'async def func(): print("执行协程函数内部代码") # 遇到IO操作挂起当前协程(任务),等IO操作完成之后,再继续往下执行,当前协程对象挂起时,事件循环可以去执行其他协程(任务) response = await others() print('IO请求结束,结果为:',response) asyncio.run(func()) |
示例三:
1 | import asyncioasync def others(): print('start') await asyncio.sleep(2) print('end') return '返回值'async def func(): print("执行协程函数内部代码") # 遇到IO操作挂起当前协程(任务),等IO操作完成之后,再继续往下执行,当前协程对象挂起时,事件循环可以去执行其他协程(任务) response1 = await others() print('IO请求结束,结果为:',response1) response2 = await others() print('IO请求结束,结果为:',response2) asyncio.run(func()) |
await就是等待对象的值得到结果之后,再继续向下走
9.1.4.4.task对象
Tasks are used to schedule coroutines concurrently.
When a coroutine is wrapped into a Task with functions like asyncio.create_task() the coroutine is automatically scheduled to the soon.
白话:在事件循环中添加多个任务的
Tasks用于并发调度协程,通过asynio.create_task(协程对象)的方式创建Task对象,这样可以让协程加入事件循环中等待被调度执行。除了使用asyncio.create_task()函数以外,还可以用更低层级的loop.create_task()和ensure_future()函数。不建议手动实例化Task对象。
注意:asyncio.create_task()函数在Python3.7中被加入。在Python3.7之前,可以改用低层级的loop.create_task()和ensure_future()函数。
示例一:
1 | import asyncioasync def func(): print('1') await asyncio.sleep(2) print('2') return '返回值'async def main(): print('main start') # 创建Task对象,将当前执行func函数添加到事件循环 task1 = asyncio.create_task(func()) task2 = asyncio.create_task(func()) print('main end') # 当执行某协程遇到IO操作时,会自动化切换执行其他任务 # 此处的await是等待相对应的协程,全部执行完毕后,然后获取结果 ret1 = await task1 ret2 = await task2 print(ret1, ret2) asyncio.run(main()) |
执行结果
1 | main startmain end1122返回值 返回值 |
示例二:
1 | import asyncioasync def func(): print('1') await asyncio.sleep(2) print('2') return '返回值'async def main(): print('main start') task_list=[ asyncio.create_task(func(),name='n1'), asyncio.create_task(func(),name='n2') ] print('main end') # done默认提供的是集合 # 如果timeout=1,执行时还没有完成,pending就是那个没有完成的东西 # 默认timeout=None,等待全部完成 done,pending = await asyncio.wait(task_list,timeout=None) print(done)asyncio.run(main()) |
结果:
1 | main startmain end1122{<Task finished name='n1' coro=<func() done, defined at F:\workspace\test.py:4> result='返回值'>, <Task finished name='n2' coro=<func() done, defined at F:\workspace\test.py:4> result='返回值'>} |
示例三:
1 | import asyncioasync def func(): print('1') await asyncio.sleep(2) print('2') return '返回值'task_list=[ func(), func(),]done,pending = asyncio.run(asyncio.wait(task_list))print(done) |
9.1.4.5.async的future对象
A Future is a special low-level awaitable object that represents an eventual result of an asynchronous operation.
Task继承Future,Task对象内部await结果的处理,基于Future对象来的。
示例一:
1 | async def main(): # 获取当前事件循环 loop = asyncio.get_running_loop() # 创建一个任务(future对象),这个任务什么都不干 fut = loop.create_future() # 等待任务最终结束(Future),没有结果会一直等下去 await fut |
示例二:
1 | import asyncioasync def set_after(fut): await asyncio.sleep(2) fut.set_result('aaa')async def main(): # 获取当前事件循环 loop = asyncio.get_running_loop() # 创建一个任务(Future)对象,没绑定任何行为,则这个任务永远不知道什么时候结束 fut = loop.create_future() # 创建一个任务(Task对象),绑定了set_after函数,函数内在2秒之后,会给fut赋值 # 即手动设置future任务的最终结果,那么future就可以结束了 await loop.create_task(set_after(fut)) # 等待Future对象获取最终结果,否则一直等待下去 data = await fut print(data)asyncio.run(main()) |
9.1.4.6.concurrent的future对象
concurrent.futures.Future
使用线程池、进程池实现异步操作时用到的对象
1 | import timefrom concurrent.futures import Futurefrom concurrent.futures.thread import ThreadPoolExecutorfrom concurrent.futures.process import ProcessPoolExecutordef func(value): time.sleep(1) print(value) return 123# 创建线程池pool = ThreadPoolExecutor(max_workers=5)# 创建进程池# pool = ProcessPoolExecutor(max_workers=5)for i in range(10): fut = pool.submit(func,i) print(fut) |
以后写代码,可能会存在交叉使用。
例如,crm项目80%都是基于协程和异步编程 + MySQL(不支持)【线程、进程做异步编程】
1 | import timeimport asyncioimport concurrent.futuresdef func1(): # 某个耗时操作 time.sleep(2) return 123async def main(): loop = asyncio.get_running_loop() # 1. Run in the default loop's executor(默认ThreadPoolExecutor) # 第一步:内部会先调用 ThreadPoolExcutor的submit方法去线程池中申请一个线程去执行func函数,并返回一个concurrent.futures.Future对象 # 第二步,调用asyncio.wrap_future将concurrent.futures.Future对象包装为asyncio.Future对象 # 因为concurrent.futures.Future对象不支持await语法,所以需要包装为asyncio.Future才能使用 fut = loop.run_in_executor(None,func1) result = await fut print('default thread pool',result) # 2.Run in a custom thread pool; # with concurrent.futures.ThreadPoolExecutor() as pool: # result = await loop.run_in_executor(pool, func1) # print('custom thread pool',result) # 3.Run in a custom process pool; # with concurrent.futures.ProcessPoolExecutor() as pool: # result = await loop.run_in_executor(pool, func1) # print('custom process pool',result)asyncio.run(main()) |
9.1.4.7.异步和非异步混合案例
案例,asyncio+不支持异步的模块
1 | import requestsimport asyncioasync def download_image(url): # 发送网络请求,下载图片(遇到网络下载图片的IO请求,自动切换到其他任务) print('download start',url) loop = asyncio.get_event_loop() # reqeusts模块不支持异步操作,所以就使用线程池来配合实现了 future = loop.run_in_executor(None,requests.get,url) resposne = await future print('download end') # 图片保存到本地 filename = url.split('/')[-1] with open(filename,'wb') as fw: fw.write(resposne.content)if __name__ =='__main__': url_list = [ 'https://pic.netbian.com/uploads/allimg/210817/235554-162921575410ce.jpg', 'https://pic.netbian.com/uploads/allimg/210816/234129-162912848931ba.jpg', 'https://pic.netbian.com/uploads/allimg/210815/233459-16290416994668.jpg', ] tasks = [download_image(url) for url in url_list] loop = asyncio.get_event_loop() loop.run_until_complete(asyncio.wait(tasks)) |
9.1.4.8.异步迭代器
什么是异步迭代器
实现饿了__aiter__()和__anext__()方法的对象,__anext__()必须返回一个awaitable对象,async_for会处理异步迭代器的__anext()__方法所返回的可等待都对象,直到其引发一个StopAsyncIteration异常。
什么时异步可迭代对象
可在async_for语句中被使用的对象,必须通过它的__aiter__()方法返回一个asynchronous iterator
1 | import asyncioclass Reader(object): # """自定义异步迭代器(同时也是异步可迭代对象)""" def __init__(self): self.count = 0 async def readline(self): # await asyncio.sleep(2) self.count += 1 if self.count == 100: return None return self.count def __aiter__(self): return self async def __anext__(self): val = await self.readline() if val == None: raise StopAsyncIteration return valasync def func(): obj = Reader() async for item in obj: print(item) asyncio.run(func()) |
9.1.4.9.异步上下文管理器
此种对象通过定义__aenter__()和aexit__()方法来对async with语句中的环境进行控制。
1 | import asyncioclass AsyncContextMannager: def __init__(self): self.conn = conn async def do_something(self): # 异步操作数据库 return 123 async def __aenter__(self): # 异步链接数据库 # self.conn = await asyncio.sleep(1) return self async def __aexit__(self,exc_type,tb): # 异步关闭数据库链接 await asyncio.sleep(1)async def func(): async with AsyncContextMannager() as f: resutl = await f.do_something() print(resutl)asyncio.run(func()) |
9.1.4.10.uvloop
是asyncio的事件循环的替代方案。事件循环 > 默认asyncio的事件循环
运行速度堪比go
1 | pip install uvloop |
注意:不支持windows
1 | import asyncioimport uvloopasyncio.set_event_loop_policy(uvloop.EventLoopPolicy())# 编写asyncio的代码,与之前的代码一致# 内部的事件循环,会由uvloop替代asyncio.run(...) |
asgi中的uvcorn,使用的就是uvloop
9.1.4.11.案例-异步操作redis
在使用python操作redis时,链接/操作/断开都是网络IO
pip install aioredis
示例一:
1 | import asyncioimport aioredisasync def execute(address,passward): print('start',address) redis = await aioredis.create_redis(address,passward=passward) # 网络IO操作 result = await redis.hmset_dict('car', key1=1, key2=2, key3=3) print(result) redis.close() # 网络IO操作,关闭redis链接 await redis.wait_closed() print('end',address)asyncio.run(execute('redis://127.0.0.2:6379','123')) |
示例二:
1 | import asyncioimport aioredisasync def execute(address,passward): print('start',address) redis = await aioredis.create_redis(address,passward=passward) # 网络IO操作 result = await redis.hmset_dict('car', key1=1, key2=2, key3=3) print(result) redis.close() # 网络IO操作,关闭redis链接 await redis.wait_closed() print('end',address)task_list = [ execute('redis://127.0.0.1:6379','123'), execute('redis://127.0.0.2:6379','123'),]asyncio.run(asyncio.wait(task_list)) |
9.1.4.12.案例-异步操作mysql
9.1.4.13.FastApi框架异步
9.1.4.14.异步爬虫
pip install aiohttp
1 | import aiohttpimport asyncioasync def fetch(session, url): print('start', url) async with session.get(url, verify_ssl = False) as response: text = await response.text() print('result:', url, len(text)) async def main(): async with aiohttp.ClientSession() as session: url_list =[ 'https://www.baidu.com', 'https://www.qq.com', 'https://pic.netbian.com/4kmeinv/' ] tasks = [asyncio.create_task(fetch(session, url)) for url in url_list] done, pending = await asyncio.wait(tasks)if __name__ == '__main__': asyncio.run(main()) |
9.1.4.15.总结
9.2.协程相关操作
9.3.多任务异步协程,实现异步爬虫
aiohttp模块
aiohttp模块引出
aiohttp+多任务异步协程,实现异步爬虫
自动化软件
selenium3
发布历史:selenium · PyPI
selenium简介
selenium模块和爬虫之间有怎样的关联?
- 便捷的获取网站中动态加载的数据
- 便捷实现模拟登录
selenium能够大幅降低爬虫的编写难度,但是也同样会大幅降低爬虫的爬取速度,在逼不得已的情况下,我们可以使用selenium进行爬虫的编写(其实能爬取到数据就行,无所谓工具)
什么是selenium模块?
- 基于浏览器自动化的一个模块
selenium是一个自动化测试工具,最初是为网站自动化测试开发的。selenium可以直接调用浏览器,它支持所有主流的浏览器(包括PhantomJS这些无界面的浏览器)。可以接受指令,让浏览器自动加载页面,获取需要的数据,甚至页面截屏等- 我们可以使用selenium很容易完成之前编写的爬虫
无头浏览器和有头浏览器的使用场景
- 通常再开发过程中,我们需要查看运行过程中的各种情况,所以使用有头浏览器(可以用docker版的ubuntu桌面版)
- 在项目完成进行部署的时候,通常平台采用的系统都是服务器版本的操作系统,服务器版的操作系统必须使用无头浏览器才能正常运行
selenium工作原理
利用浏览器原生的API,封装成一套更加面向对象的
Selenium WebDriver API,直接操作浏览器页面里的元素,甚至操作浏览器本身(截图、窗口大小、启动、关闭、安装插件、配置证书之类的)
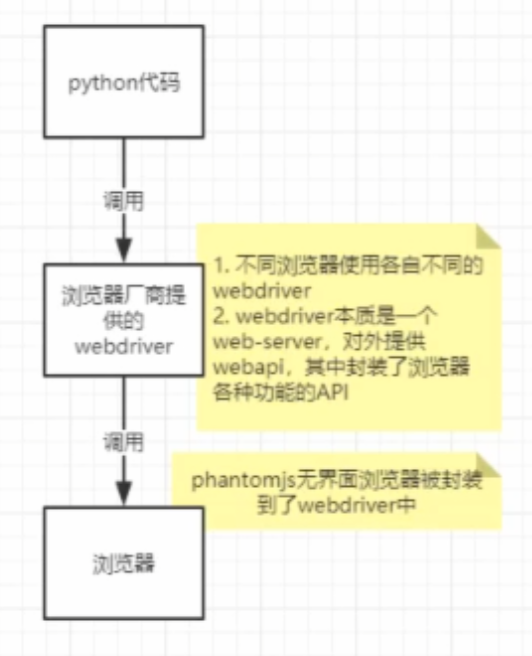
webdriver本质是一个web-server,对外提供webapi,其中封装了浏览器的各种功能- 不同的浏览器使用各自不同的
webdriver- 因为不同的浏览器,虽然功能是一致的,但不同浏览器厂商实现的代码细节都是不同的
selenium初试
selenium使用流程
环境安装:
pip install selenium安装谷歌浏览器:如
Version 114.0.5735.106 (Official Build) (64-bit)下载浏览器的驱动程序
webdriver下载链接:http://npm.taobao.org/mirrors/chromedriver/
搜索到对应的
webdriver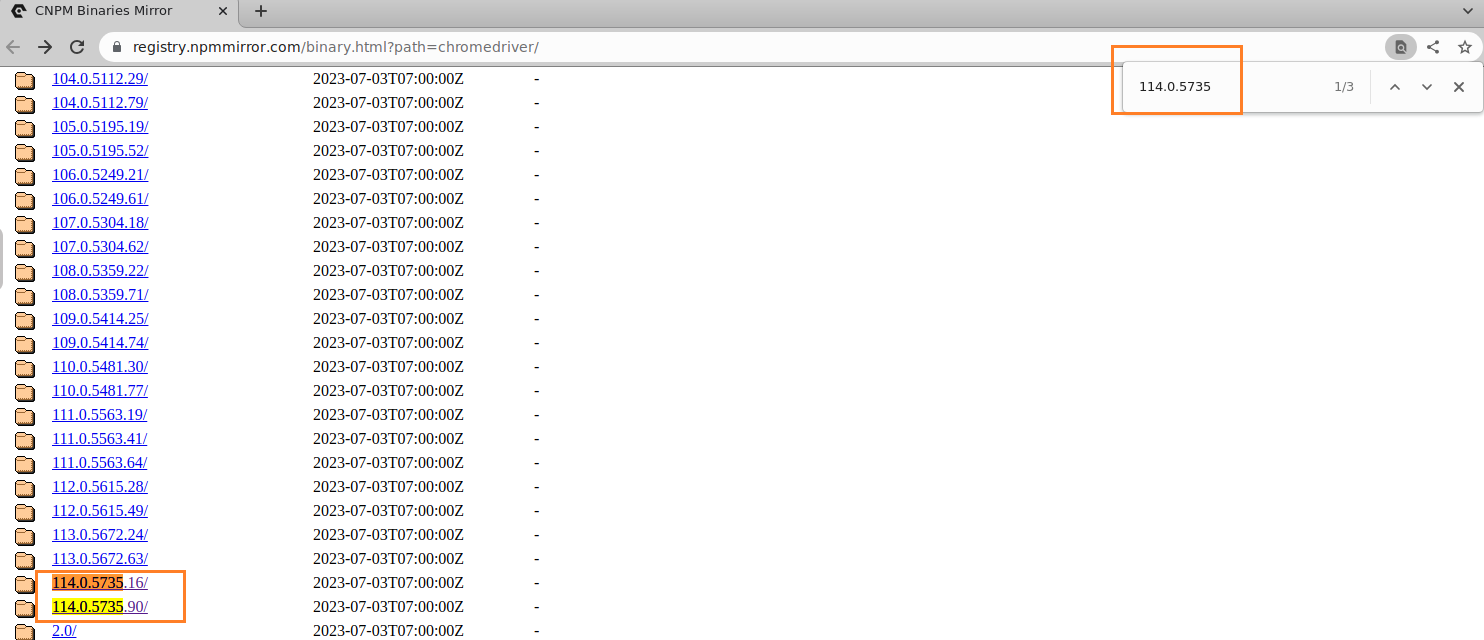

如果没有自己对应浏览器版本的
chromedriver,则选择高一点的chromedriver版本或者更换浏览器版本驱动程序和浏览器的对应关系:https://blog.csdn.net/huilan_same/article/details/51896672
解压后获取
python代码可以调用的谷歌浏览器的webdriver可执行文件windows为chromedriver.exelinux和mac为chromedriver
chromedriver环境的配置windows环境下需要将chromedriver.exe所在的目录设置为path环境变量中的路径linux/mac环境下,将chromedriver所在的目录设置到系统的PATH环境值中查看
$PATH第一个是之前自己配置的路径,将
webdriver复制进去即可1
2
3
4echo $PATH
/app/env/env_python_data/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/app/env/.nvm/nvm:/app/env/.nvm/nvm
cp chromedriver /app/env/env_python_data/bin任意目录启动
1
2
3
4
5
6
7chromedriver
Starting ChromeDriver 114.0.5735.16 (7e1ff058633f5b79b1cd7479aca585ba385519d8-refs/branch-heads/5735@{#182}) on port 9515
Only local connections are allowed.
Please see https://chromedriver.chromium.org/security-considerations for suggestions on keeping ChromeDriver safe.
[1688369881.439][SEVERE]: bind() failed: Cannot assign requested address (99)
ChromeDriver was started successfully.一种说法是要放在
python安装目录的Scripts文件夹下,但linux下没有该文件夹如果实在找不到对应版本的驱动或浏览器,可以尝试下再edgedriver:https://msedgewebdriverstorage.z22.web.core.windows.net/?prefix=114.0.1823.41/
如果是
ubuntu系统,始终无法得到正确的页面检查
sudo vim /usr/bin/micorsoft-edge或者是sudo,如果设置了–user-data-dir,这个时候就会出现错误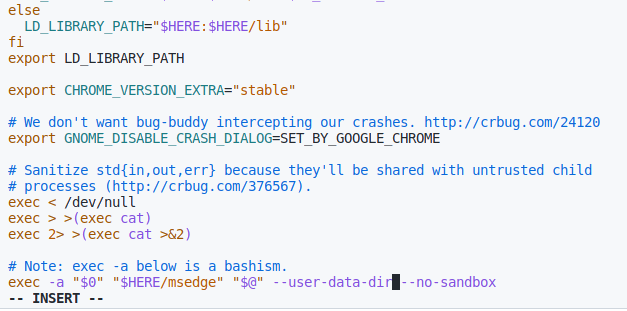
1
2
3
4
5
6selenium.common.exceptions.WebDriverException: Message: unknown error: Microsoft Edge failed to start: exited normally.
(unknown error: DevToolsActivePort file doesn't exist)
(The process started from msedge location /usr/bin/microsoft-edge is no longer running, so msedgedriver is assuming that msedge has crashed.)
Stacktrace:
#0 0x565443614fd3 <unknown>
...直观的感受是,
url始终是data:,且页面为空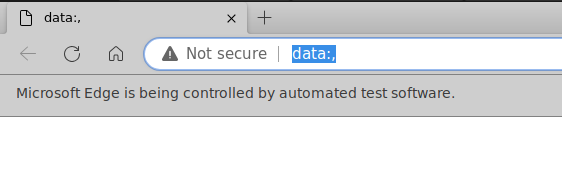
如果是
chrome浏览器,启动配置也需要修改:
编写基于浏览器自动化的操作代码
例一:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22import time
from selenium import webdriver
# 通过指定chromedriver的路径来实例化driver对象,chromedriver放在当前目录
# driver = webdriver.Chrome(executable_path = './chromedriver')
# 也可以控制edge浏览器
# driver = webdriver.Edge(executable_path = './msedgedriver')
# 也可以将chromedriver文件复制到到环境变量所在的路径下
driver = webdriver.Chrome()
# 控制浏览器访问url地址
driver.get('https://www.baidu.com')
# 在百度搜索框中搜索'python'
driver.find_element_by_id('kw').send_keys('python')
# 点击百度搜索
driver.find_element_by_id('su').click()
time.sleep(6)
# 退出浏览器
driver.quit()例二:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15from selenium import webdriver
from lxml import etree
from time import sleep
# 实例化一个浏览器对象(传入浏览器的驱动程序)
bro = webdriver.Chrome(executable_path = './chromedriver.exe')
# 让浏览器发起一个指定url对应请求
bro.get('http://npm.taobao.org/mirrors/chromedriver/92.0.4515.107/')
# 获取浏览器当前页面的源码数据
page_text = bro.page_source
# 解析字段
tree = etree.HTML(page_text)
src = tree.xpath('//div[@class="container"]/pre/a/@href')
for i in range(0,len(src)):
print(src[i])sleep(5)
bro.quit()例三(edge)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27# selenium 4
from selenium import webdriver
from selenium.webdriver.edge.service import Service
from selenium.webdriver.edge.options import Options
from time import sleep
# 设置Edge浏览器的驱动路径
edge_driver_path = './msedgedriver'
# 创建Edge浏览器的选项对象
options = Options()
# 可根据需要添加更多的选项
# 创建Edge浏览器的服务对象
service = Service(edge_driver_path)
# 创建Edge浏览器的WebDriver对象
driver = webdriver.Edge(service=service, options=options)
# 打开网页
driver.get('https://msedgewebdriverstorage.z22.web.core.windows.net/')
# 进行其他操作,例如查找元素、点击按钮等
sleep(5)
# 关闭浏览器
driver.quit()注意点:谷歌中文官网上的浏览器,默认安装在c盘,安装之后不要移动目录,否则驱动无法检测。
driver对象常用属性和方法
driver.page_source- 当前标签页浏览器渲染之后的网页源代码
driver.current_url- 当前标签页的
url
- 当前标签页的
driver.close()- 关闭当前标签页,如果只有一个标签页则关闭整个浏览器
driver.quit()- 关闭浏览器
driver.forward()- 页面前进
driver.back()- 页面后退
driver.screen_shot(img_name)- 页面截图(可用来处理验证码)
1 | from time import sleep |
selenium元素定位
find_element_by_id()- 返回一个元素
find_element(s)_by_class_name()- 返回类名获取的元素列表
find_element(s)_by_name()- 根据标签的
name属性值,返回包含标签对象元素的列表
- 根据标签的
find_element(s)_by_xpath()- 返回一个包含元素的列表
find_element(s)_by_link_text()- 根据链接文本获取元素列表
find_element(s)_by_partial_link_text()- 根据链接包含的文本获取元素列表
find_element(s)_by_tag_name()- 根据标签名称获取元素列表
find_element(s)_by_css()- 根据
css选择器来获取元素列表
- 根据
注意:
find_element和find_elements的区别- 多了个
s就返回列表,没有s就返回匹配到的第一个标签对象 find_element匹配不到就抛出异常,find_elements匹配不到就返回空列表
- 多了个
by_link_text和by_partial_link_text的区别:全部文本和包含某个文本- 以上函数的使用方法:
driver.find_element_by_id('id_str')
1 | # 掌握xpath即可 |
selenium元素操作
- 获取文本
elements.text- 通过定位获取的标签对象的
text属性,获取文本内容
- 获取属性值
element.get_attribute('属性名')- 通过定位获取的标签对象的
get_attribute函数,传入属性名,来获取属性值
- 输入值
element.send_keys(data)
- 清除值
element.clear()
selenium的其他方法
- 控制标签页切换
- 控制
iframe切换 - 获取
cookie - 执行
js代码 - 手动实现页面等待
- 开启无界面模式
- 使用代理
ip - 替换
User-Agent
控制标签页切换
获取所有标签页的窗口句柄
利用窗口句柄字切换到句柄指向的标签页
- 这里的窗口句柄是指:指向标签页对象的标识
具体方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20from time import sleep
from selenium import webdriver
driver = webdriver.Edge(executable_path = './msedgedriver')
url = 'https://jn.58.com/'
driver.get(url)
print(driver.current_url) # https://jn.58.com/
print(driver.window_handles) # ['00D09D20C37EC988C45DBFEE9575142B']
# 定位并点击“租房”按钮
el = driver.find_element_by_xpath('//*[@id="fcNav"]/*/a[@tongji_tag="pc_home_dh_zf"]')
el.click()
print(driver.current_url) # https://jn.58.com/ 操作权还没有切换
print(driver.window_handles) # ['AC534938D0295589F1F85C665EA181EA', '3084128DB37C2719E27400EDDB8FD179']
# 切换窗口,不切换的话,后续元素获取不到
driver.switch_to.window(driver.window_handles[-1])
title_list = driver.find_elements_by_xpath('//*[@class="des"]/h2/a')
print(len(title_list)) # 122
控制iframe切换
应用场景:登陆
1 | from time import sleep |
注意:有的id是时间辍id,是动态变化的

iframe处理+动作链
1 | from selenium import webdriver |
操作cookie
1 | from time import sleep |
执行js代码
场景:上下滚屏
1 | from time import sleep |
页面等待
浏览器资源请求及渲染机制:
页面等待分类
强制等待(了解)
- 其实就是
time.sleep(3) - 缺点是不智能,设置的时间太短,元素还没有加载出来;设置的时间太常,则会浪费时间
- 其实就是
显示等待(了解,一般用在测试)
每经过多少秒就查看一次等待条件时都达成,如果达成就停止等待,继续执行后续代码
如果没有达成就继续等待,知道超过规定的时间后,报超时异常
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
# 需要selenium4
driver = webdriver.Edge()
driver.get('https://www.baidu.com')
# 显式等待
'''
# 参数20表示最长等待20秒
# 参数0.5表示每0.5秒检查一次规定的标签是否存在
# EC.presence_of_element_located(By.LINK_TEXT, '好123') 表示通过链接文本内容定位位置
# 每0.5秒进行一次检查,通过链接文本内容定位标签是否存在,如果存在就向下继续执行;如果不存在,重复定位直到20秒上限就报错
'''
WebDriverWait(driver, 20, 0.5).until(
EC.presence_of_element_located(By.LINK_TEXT, '好123')
)
隐式等待
针对的是元素定位,隐式等待设置了一个时间,在一段时间内判断元素是否定位成功,如果完成了,就进行下一步
在设置的时间内没有定位成功,则会报超时加载
1
2
3
4
5
6
7
8
9
10
11
12from time import sleep
from selenium import webdriver
import json
driver = webdriver.Edge(executable_path = './msedgedriver')
# 设置隐式等待,所有元素定位操作,都有最大的等待时间,超过10秒后将会报错
driver.implicitly_wait(10)
url = 'https://www.baidu.com'
driver.get(url)
el = driver.find_element_by_xpath('//*[!id="lg"]/img[1000]')
print(el)
手动实现页面等待
我们发现并没有一种通用的方法,来解决页面等待的问题。比如“页面需要滑动才能触发
ajax异步加载”的场景。接下来以淘宝网首页为例,手动实现页面等待1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22# 利用强制等待和显式等待的思路来手动实现
# 不同的判断或有次数限制的判断,某一标签对象是否加载完毕(是否存在)
from time import sleep
from selenium import webdriver
import json
driver = webdriver.Edge(executable_path = './msedgedriver')
driver.get('https://www.taobao.com')
sleep(1)
for i in range(10):
i += 1
try:
sleep(3)
element = driver.find_element_by_xpath('//div[@class="shop-inner"]/h3[1]/a')
print(element.get_attribute('href'))
break
except:
js = 'window.scrollTo(0,{})'.format(i*500)
driver.execute_script(js)
driver.quit()
开启无界面模式
绝大多数服务器是没有界面的(也可以使用
docker搭建ubuntu有界面的),selenium控制台谷歌浏览器也是存在无界面模式的(又称之为无头模式)
开启无界面模式的方法
- 实例化配置对象
options = webdriver.ChromeOptions()
- 配置对象添加开启无界面模式的命令
options = webdriver.Chrome(chrome_options = options)
- 实例化配置对象
注意:
macos中的chrome浏览器59+版本,linux中57+版本才能使用无界面模式参考代码(使用
selenium4的语法):1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32# selenium 4
from selenium import webdriver
from selenium.webdriver.edge.service import Service
from selenium.webdriver.edge.options import Options
from time import sleep
url = 'https://www.baidu.com'
# 设置Edge浏览器的驱动路径
edge_driver_path = './msedgedriver'
# 创建Edge浏览器的选项对象
options = Options()
# 可根据需要添加更多的选项
options.add_argument('--headless')
options.add_argument('--disable-gpu')
# 创建Edge浏览器的服务对象
service = Service(edge_driver_path)
# 创建Edge浏览器的WebDriver对象
driver = webdriver.Edge(service=service, options=options)
# 打开网页
driver.get('https://msedgewebdriverstorage.z22.web.core.windows.net/')
# 进行其他操作,例如查找元素、点击按钮等
sleep(3)
driver.save_screenshot('08.png')
# 关闭浏览器
driver.quit()
无头浏览器+规避检测
现在不少大网站对selenium采取了检测机制。比如正常情况下我们用浏览器访问淘宝等网站的window.navigator.webdriver的值为undefined。而使用selenium访问该值为true。那么如何解决这个问题呢?
只需要设置Chromedriver的启动参数即可。在启动Chromedriver之前,为Chrome开启实验性功能参数excludeSwitches,它的值为['enable-automation'],完整代码如下:
1 | from selenium import webdriver |
使用代理ip
使用代理
ip的方法实例化配置对象
options = webdriver.ChromeOptions()
配置对象添加使用代理
ip的命令options.add_argument('--proxy-server=http://202.20.16.82:9527')
实例化带有配置对象的
driver = webdriver.Chrome('./chromdriver', chrome_options=options)参考代码:
1
options.add_argument('--proxy-server=http://202.20.16.82:9527')
缺点:更换
ip代理,必须重新实例化(重启)
替换User-Agent
1 | options.add_argument('--user-agent=Mozilla/5.0') |
selenium案例
1 | # 斗鱼 |
selenium其他自动化操作
- 编写基于浏览器自动化的操作代码
- 发起请求:
get(url) - 标签定位:find系列的方法
- 标签交互:
send_keys('xxx') - 执行js程序:
excuted_script('jsCode') - 前进、后退:
back()、forward() - 关闭浏览器:
quit()
- 发起请求:
1 | from selenium import webdriver |
超级鹰的基本使用
selenium4
playwright
爬虫框架
scrapy
scrapy框架初识
什么是框架
- 我们知道常用的流行web框架有django、flask,那么接下来,我们会来学习一个全世界范围最流行的爬虫框架
- 就是一个集成了很多的功能,并且 有很强通用性的一个项目模板。
如何学习框架
- 专门学习框架封装的各种功能的详细用法
什么是scrapy
- 爬虫中封装好的一个明星框架。
- 功能:高性能的持久化存储,异步的数据下载,高性能的数据解析,分布式。
内容
scrapy的该概念作用和工作流程scrapy的入门使用scrapy模拟登陆scrapy管道的使用scrapy中间件的使用scrapy_redis概念作用和流程scrapy_splash组件的使用scrapy日志信息与配置scrapy部署scrapy项目
12.2.scrapy环境安装
环境安装
linux或mac系统
pip install scrapy
windows系统
pip install scrapy测试:在终端里录入
scrapy命令,没有报错即表示安装成功。
12.3.scrapy基本使用
scrapy使用流程
创建工程
scrapy startproject ProName
进入工程目录
cd ProName
创建爬虫文件
scrapy genspider SpiderName www.xxx.com1
import scrapyclass FirstSpider(scrapy.Spider): # 爬虫文件的名称,就是爬虫文件的唯一标识 name = 'first' # 允许的域名:用来限定start_urls中,哪些url可以进行请求发送 allowed_domains = ['www.baidu.com'] # 起始的url列表:该列表中存放的url会被scrapy自动的进行请求的发送,可以有多个 start_urls = ['http://www.baidu.com/','http://www.sogou.com'] # 作用于数据解析:response参数表示的就是,请求成功后对应的响应对象 # 会被调用多次,由start_urls中的元素个数决定的 def parse(self, response): pass
设置
ROBOTSTXT=False设置
LOG_LEVEL='ERROR'1
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3947.100 Safari/537.36'# Obey robots.txt rulesROBOTSTXT_OBEY = FalseLOG_LEVEL = 'ERROR'
编写相关操作代码
执行工程
scrapy crawl SpiderName
12.4.scrapy数据解析
爬取糗事百科https://www.qiushibaike.com/text/
1 | import scrapyclass QiushiSpiderSpider(scrapy.Spider): name = 'qiushi_spider' # allowed_domains = ['www.xxx.com'] start_urls = ['https://www.qiushibaike.com/text/'] def parse(self, response): # 解析作者的名称+段子内容 div_list = response.xpath('//div[@class="col1 old-style-col1"]/div') # print(div_list) for div in div_list: # xpath返回的是列表,但是列表元素一定是selector类型的对象 # extract可以将selector对象中,data参数的存储的字符串提取出来 # author = div.xpath('./div[1]/a[2]/h2/text()')[0].extract() author = div.xpath('./div[1]/a[2]/h2/text()').extract_first() # 如果列表调用了extract之后,则表示将列表中的每一个selecor对象中data对应的字符串提取了出来 content = div.xpath('./a[1]/div/span//text()').extract() content = ''.join(content) print(author,content) break |
设置USER_AGENT
运行scrapy crawl qiushi_spider
12.5.持久化存储
12.5.1.基于终端指令的持久化存储
只可以将parse方法的返回值存储到本地的文本文件中。
注意:持久化存储对应的文本文件的类型,只可以为:json、jsonlines、jl、csv、xml、marshal、pickle
指令:scrapy crawl qiushi_spider -o ./qiushi.csv
好处:简洁高效便捷
缺点:局限性比较强(数据只可以存储到指定后缀的文本文件中)
12.5.2.基础管道持久化存储
编码流程:
数据解析
在iem类中定义相关的属性
将解析的数据,封装存储到item类型的对象中
1
# items.pyimport scrapyclass QiushiItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() author = scrapy.Field() content = scrapy.Field() # pass
将item类型的数据,提交给管道进行持久化存储的操作
在管道类的process_item中,要将其接收到的item对象中存储的数据,进行持久化存储操作
process_item
- 专门用来处理item类型的对象
- 该方法可以接收爬虫文件提交过来的item对象
- 该方法没接收一个item,就会被调用一次
1
# pipelines.pyfrom itemadapter import ItemAdapterclass QiushiPipeline: fp = None # 重写父类的方法,该方法只会在开始爬虫的时候,被调用一次 def open_spider(self, spider): print('爬虫开始...') self.fp = open('./qiushi.txt','w',encoding='utf-8') # 专门用来处理item类型对象 def process_item(self, item, spider): author = item['author'] content = item['content'] self.fp.write(author + ':' + content + '\n') return item # 这里如果写了return,则item会传递给下一个即将执行的管道类,默认都是加上 # 结束爬虫时,会被调用一次 def close_spider(self,spider): print('爬虫结束...')
在配置文件中开启管道
1
ITEM_PIPELINES = { # 数值表示优先级,数值越小,优先级越高 'qiushi.pipelines.QiushiPipeline': 300,}
备注:如果有匿名用户,则会报错
完善author的xpath:
1
autho = div.xpath('./div[1]/a[2]/h2/text() | ./div[1]/span/h2/text()').extarct_first()
好处:通用性强
面试题:将爬取到的 数据一份存储到本地,一本存储到数据库,如何实现?
在管道文件中定义多个管道类:
1
# 管道文件中,一个管道类对应将一组数据存储到一个平台或一个载体中class mysqlPipeline(object): conn = None pool = None value = '' def open_spider(self, spider): self.pool = ConnectionPool(host='127.0.0.1',port=6379,password='foobared', decode_responses=True) def process_item(self, item, spider): self.conn = Redis(connection_pool=self.pool) self.conn.set('k1','v1') value = self.conn.get('k1') def close_spider(self, spider): print(self.value)
在
ITEM_PIPELINES中配置:1
ITEM_PIPELINES = { 'qiushi.pipelines.QiushiPipeline': 300, 'qiushi.pipelines.redisPipeline': 301,}
爬虫文件提交的item,只会给管道文件中第一个被执行的管道类接受
process_item中的return item表示将item传递给下一个即将执行的管道类
12.6.全站数据爬取
基于Spider的全站数据爬取
就是将网站中某板块下的全部页码,对应的页面数据进行爬取
需求:爬取校花网中的照片的名称
实现方式:
将所有页面的url添加到start_urls列表(不推荐)
自行手动进行请求发送
1
import scrapyclass XiaohuaSpider(scrapy.Spider): name = 'xiaohua' # allowed_domains = ['www.xx.com'] start_urls = ['http://www.521609.com/tuku/index.html'] # 生成一个通用的url模板(不可变的) url = 'http://www.521609.com/tuku/index_%d.html' page_num = 2 def parse(self, response): li_list = response.xpath('/html/body/div[4]/div[3]/ul/li') for li in li_list: img_name = li.xpath('./a/p/text()').extract_first() print(img_name) if self.page_num <= 3: new_url = format(self.url % self.page_num) self.page_num += 1 # 手动发送请求,callback回调函数专门用作数据解析 yield scrapy.Request(url = new_url, callback = self.parse)
12.7.五大核心组件
- 引擎(scrapy)
- 用来处理整个系统的数据流处理,触发事务(核心)
- 调度器(Scheduler)
- 用来接受引擎发过来的请求,压入队列中,并在引擎再次请求的时候返回。可以想象成要给URL(抓取网页的网址或者是链接)的优先队列,由它来决定下一个要抓取的网址是什么,同时去除重复的网址。
- 下载器(Downloader)
- 用于下载网页内容,并将网页内容返回给引擎,下载器是建立在twisted这个高效的异步模型上的。
- 爬虫(Spiders)
- 爬虫是用来干活的,用于从特定网页中提取自己需要的信息,即所谓的实体(item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面。
- 项目管理(Pipeline)
- 负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体,验证实体信息有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管理,并经过几个特定的次序处理数据。
12.7.1.请求传参
- 使用场景:如果爬取解析的数据不在同一张页面中。我们就需要用到请求传参(深度爬取)
- 需求:爬取boss的岗位名称,岗位描述
如果要使用管道进行持久化存储,需要先在item.py中定义item:
1 | class BossproItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() # pass title = scrapy.Field() describe = scrapy.Field() |
然后导入item中的类:
1 | from bosspro.items import BossproItem |
然后在for循环中实例化item对象,把需要的字段,存到item类型的字段中:
1 | item = BossproItem()item['title'] = titleyield scrapy.Request(title_href,callback=self.parse_detail,meta={'item':item}) |
在回调的解析方法中,接受item对象,并传入该解析方法特有的值,最后返回item给管道:
1 | item = response.meta['item']item['describe'] = describeyield item |
分页爬取
定义url模板
1
template_url = 'http://news.longhoo.net/njxw/%d.html'page_num = 2
在首个url的parse方法中,进行分页操作
1 | if self.page_num <= 3: next_url = format(self.template_url % self.page_num) self.page_num += 1 yield scrapy.Request(next_url, callback=self.parse) |
练习:
12.7.2.scrapy图片爬取
基于scrapy爬取字符串类型的数据,和爬取图片类型的数据的区别?
- 字符串:只需要进行xpath进行解析,且提交到管道进行持久化存储。
- 图片:xpath解析出图片的src的属性值。单独的对图片地址发起请求获取图片二进制类型的数据。
ImagePipeline:
- 只需要将Img的src的属性值进行解析,提交到管道,管道就会对图片的src进行请求发送获取图片的二进制类型数据,且还会帮我们进行持久化存储。
- 需求:爬取图片网的图片
使用流程:
- 数据解析(获取图片地址)
- 在管道文件中,自定义一个基于ImagesPipeline的一个管道类
- get _media_request
- file_path
- item_completed
- 在配置文件中:
- 指定图片存储路径:
IMAGES_STORE='./imgs' - 指定开启的管道:自定义管道类
- 指定图片存储路径:
注意点:
默认的管道类,是不处理图片格式的数据的。
ImagesPipeline专门用于文件下的管道类,下载过程支持异步和多线程
重写父类的三个方法
1
# Define your item pipelines here## Don't forget to add your pipeline to the ITEM_PIPELINES setting# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# useful for handling different item types with a single interfacefrom itemadapter import ItemAdapterfrom scrapy.pipelines.images import ImagesPipelineimport scrapy# class GirlpicPipeline:# def process_item(self, item, spider):# return itemfrom girlpic.items import GirlpicItemclass girlPipeline(ImagesPipeline): # 对item中的图片进行请求操作 def get_media_requests(self, item, info): # return super().get_media_requests(item, info) yield scrapy.Request(item['src']) # 定制图片的名称 # def file_path(self, request, response, info, *, item): # return super().file_path(request, response=response, info=info, item=item) def file_path(self, request, response=None, info=None): item = GirlpicItem() image_name = item['image_name'] return image_name # def item_completed(self, results, item, info): # return super().item_completed(results, item, info) # 返回给下一个即将被执行的管道类中 return item
在settings.py中,定义图片的存储目录
IMAGES_STORE = './imgs'如果路径不存在,则会自行创建
在settings.py中,开启指定的管道类
图片懒加载
- 有些图片的src属性,写成src2之类的,只有元素被滑动到可视窗口中是,才会切换成src属性。
- 在xpath提取的时候,得提取src2属性。
- 有的图片懒加载,变化的是是src的值,这时候得用其他属性,直接用src属性,可能会有问题。
12.7.3.中间件
12.7.3.1.中间件初始
- 下载中间件
- 位置:引擎和下载器之间
- 作用:批量拦截到整个工程中所有的请求和响应
- 拦截请求:
- UA伪装
- 代理IP
- 拦截响应:
- 篡改响应数据,响应对象
12.7.3.2.中间件-处理请求
爬虫中间件
下载中间件
process_request
用来拦截请求
UA伪装
1
def process_request(self, request, spider): request.headers['User-Agent'] = random.choice(self.user_agent_list) request.meta['proxy'] = 'http://183.151.202.233:9999' return None
process_response
- 用来所有的拦截响应
- 需求:爬取网易新闻中的新闻数据(标题和内容)
- 1.通过网易新闻
process_exception
用来拦截发生异常的请求对象
代理ip:process_exception:return request
1
def process_exception(self, request, exception, spider): # 代理 if request.url.split(':')[0] == 'http': request.meta['proxy'] = 'http:' + random.choice(self.PROXY_http) else: request.meta['proxy'] = 'https:' + random.choice(self.PROXY_https) # 将修正后的请求对象,重新发送 return request
settings.py中开启中间件
12.7.4.中间件-处理响应
案例:网易新闻
通过网易新闻的首页解析五大板块对应的详情页的url(没有动态加载)
每一个板块对应的新闻标题都是动态加载的出来的(动态加载)
使用下载中间件的process_response,篡改响应对象
1
def process_response(self, request, response, spider): bro = spider.bro # 挑选指定的响应对象进行篡改 # 通过传入的url和爬虫中的存的url进行判断 # 匹配上的话,就篡改对应的response对象 if request.url in spider.category_urls: # 传入目标板块的response # 针对定位的response进行篡改 # 实例化一个新的响应对象(符合需求,包含动态加载出来的新闻数据),替代原来旧的响应对象 # 基于selenium获取动态加载数据 bro.get(request.url) sleep(2) page_text = bro.page_source new_response = HtmlResponse(url=request.url, body=page_text, encoding='utf-8', request=request) return new_response else: return response
在爬虫文件的init方法中,实例化浏览器对象
1
def __init__(self): self.bro = webdriver.Chrome(executable_path='./chromedriver.exe')
通过解析出每一新闻详情页的url获取详情页的页面源码,解析出新闻内容
12.7.5.crawlspider的全站数据爬取
Crawlspider:Spider的一个子类
- 全站数据爬取的方式
- 基于Spider:手动请求
- 基于CrawlSpider
- CrawlSpider的使用:
- 创建一个工程
- cd xxx
- 创建爬虫文件(CrawlSpider)
scrapy genspider -t crawl xxx www.xxx.com
- 启动爬虫文件
scrapy crawl 文件名
- 链接提取器
- 根据指定规则
(allow="正则")进行执行链接的提取 - 注意特殊字符,在正则表达式中的转义,比如
?
- 根据指定规则
- 规则解析器
- 将链接提取器提取到的链接,进行指定规则
(callback)的解析操作 - follow=True,则意味着对解析出来的url页面,再重复按照相同的规则进行提取,并去重。
- 将链接提取器提取到的链接,进行指定规则
12.7.5.1.练习
- https://wz.sun0769.com/political/index/politicsNewest?id=1&page=0
- 爬取编号,新闻标题,内容
- 二级页编号要多爬取一次
- 可以设置多个链接提取器
12.8.分布式
12.8.1.分布式概述
分布式爬虫
- 概念:我们需要搭建一个分布式的集群,让其对一组资源进行分布联合爬取。
- 作用:提升爬取效率
如何实现分布式
- 安装一个scrapy-redis组件
- 原生的scrapy是不可以实现分布式爬虫的,必须要让scrapy结合着scrapy-redis组件,一起实现分布式爬虫。
12.8.2.分布式搭建
创建一个工程
创建一个基于CrawlSpider的爬虫文件
修改当前的爬虫文件
- 导包:
from scrapy_redis.spiders import RedisCrawlSpider - 将
strat_urls和allowed_domains进行注释 - 添加一个新属性:
redis_key = 'sun',表示可以被共享的调度器队列的名称 - 编写数据解析相关的操作
- 将当前爬虫类的父类修改成RedisCrawlSpider
- 导包:
修改配置文件,末尾添加
1
# 指定管道ITEM_PIPELINES = { 'scrapy_redis.pipelines.RedisPipeline' : 400}# 指定调度器# 增加了一个去重容器类的配置,作用使用Redis集合来存储请求的指纹数据,从而实现请求去重的持久化DUPEFILTER_CLASS ='scrapy_redis.dupefilter.RFPDupeFilter'# 使用scrapy_redis组件自己的调度器SCHEDULER = 'scrapy_redis.scheduler.Scheduler'# 配置调度器是否要持久化,也就是当爬虫结束了,要不要清空Redis中请求队列和去重指纹的set。如果是,TrueSCHEDULER_PERSIST = True# 指定redisREDIS_HOST = '127.0.0.1'REDIS_PORT = '6379'REDIS_PARAMS = { 'password': '123123', }
redis相关配置操作
若是云主机,在控制台开启对应端口
注释 bind
关闭保护模式:protected mode = no
后台启动redis
启动客户端
执行工程
- 进入到爬虫文件所在的目录,执行
scrapy runspider xxx.py - 向调度器的队列中,放入起始url
- 调度器的队列在redis的客户端中
lpush key url
- 调度器的队列在redis的客户端中
- 进入到爬虫文件所在的目录,执行
爬取到的数据存储在了redis的proName:items这个数据结构中
12.8.3.增量式爬虫
- 概念:监测网站数据实时更新的情况,只会爬取网站最新更新出来的数据
- 分析:
- 指定一个起始url
- 基于CrawlSpider获取其他页码链接
- 基于Rule将其他页码链接进行请求
- 从每一个页码对应的页面源码中,解析出每一个电影详情页的url
- 核心:
- 检测电影详情页的url之前有没有被请求过
- 将爬取过的电影详情页的url存储
- 对详情页的url发起请求,然后解析出电影名称和简介
- 进行持久化存储
自研框架
数据入库
入库流程及注意点
将爬虫抓取的数据进行有效的存储和管理是一个重要的步骤,以下是一套常见的数据入库方案,供您参考:
- 选择数据库系统: 根据您的需求和数据特性,选择合适的数据库系统。常见的数据库包括关系型数据库(如MySQL、PostgreSQL)、NoSQL数据库(如MongoDB、Redis)等。选择数据库时需要考虑数据结构、性能、扩展性等因素。
- 设计数据模型: 在选定的数据库中,设计适当的数据模型。这涉及创建表、定义字段和数据类型。确保模型能够有效地存储您的数据,以及支持未来的查询和分析需求。
- 数据清洗与转换: 在将数据存入数据库之前,对爬取的数据进行清洗和转换。去除重复数据、处理缺失值、格式化数据等操作,以保证数据的准确性和一致性。
- 建立连接: 使用合适的数据库连接库或驱动程序,建立与选定数据库的连接。根据所选数据库系统的不同,连接的方式和步骤会有所不同。
- 插入数据: 使用数据库提供的API,将清洗后的数据插入到相应的表中。对于大批量数据插入,可以考虑使用批量插入或事务处理,以提高性能和数据一致性。
- 建立索引: 为需要频繁查询的字段创建索引,以加快查询速度。索引能够显著提升数据库的检索性能,但也会增加数据写入的开销。
- 定时更新: 如果您的爬虫是周期性运行的,考虑定时更新数据库中的数据。这可以通过比较已有数据和新爬取数据的方式来更新、插入或删除数据。
- 数据备份与恢复: 实施定期的数据备份策略,确保数据的安全性。在数据库出现故障或数据丢失时,能够进行快速的数据恢复。
- 性能优化: 随着数据量的增加,数据库性能可能会受到影响。进行性能优化,如查询优化、合理使用数据库缓存、分库分表等,以确保数据库的高效运行。
- 安全考虑: 实施数据库的安全策略,包括访问控制、数据加密、防止SQL注入等,以保护数据的安全性和隐私。
- 监控与报警: 部署监控系统,实时监测数据库的性能和运行状态,设置警报以便及时处理潜在的问题。
- 容灾与扩展: 考虑数据库的容灾和扩展策略,以应对突发情况和未来的业务增长。
总之,数据入库方案需要综合考虑数据特性、业务需求、性能要求等多个因素。根据具体情况,您可能需要进行适当的调整和定制。
postgres
当您有一些 JSON 数据需要存储到 PostgreSQL 数据库时,您可以使用 Python 和 psycopg2 库来实现。以下是一个简单的示例代码,展示了如何将 JSON 数据插入到 PostgreSQL 数据库中:
首先,确保您已经安装了 psycopg2 库。如果没有安装,可以使用以下命令进行安装:
1 | pip install psycopg2 |
然后,您可以使用以下代码示例来插入 JSON 数据到 PostgreSQL 数据库中:
1 | import psycopg2 |
在上面的示例中,我们首先定义了数据库连接参数,然后创建了一个包含 JSON 数据的列表。接着,我们使用 psycopg2 建立数据库连接,并创建了一个名为 “json_data” 的表,该表有一个 “data” 列用于存储 JSON 数据。
然后,我们遍历 JSON 数据列表,使用 SQL 插入语句将 JSON 数据插入到数据库中。
最后,我们提交事务并关闭数据库连接。
psycopg2
psycopg2.connect() 是 psycopg2 库中用于建立与 PostgreSQL 数据库连接的函数。它接受多个参数,用于配置连接的各个方面。以下是常用的参数列表:
dbname (或 database):要连接的数据库名称。
user:连接数据库所用的用户名。
password:连接数据库所用的密码。
host:数据库服务器的主机名或IP地址。
port:数据库服务器监听的端口号,默认为 5432。
connection_factory:一个自定义的连接工厂,用于创建连接对象。
cursor_factory:一个自定义的游标工厂,用于创建游标对象。
sslmode:设置与服务器的连接是否使用 SSL 加密。可选值为 “disable”、”allow”、”prefer”、”require”、”verify-ca” 和 “verify-full”。
sslrootcert:SSL 根证书的路径,用于验证服务器证书。
options:options` 参数用于指定一些额外的连接选项,以字符串形式提供。这些选项可以影响连接的行为和性能。
- search_path:设置数据库搜索路径,指定默认的模式(schema)。示例:
"-c search_path=test" - application_name:设置客户端应用程序名称,用于在服务器端标识连接的来源。示例:
"-c application_name=MyApp" - sslmode:设置与服务器的连接是否使用 SSL 加密。可选值为 “disable”、”allow”、”prefer”、”require”、”verify-ca” 和 “verify-full”。示例:
"-c sslmode=require" - client_encoding:设置客户端的字符编码。示例:
"-c client_encoding=UTF8" - timezone:设置客户端的时区。示例:
"-c timezone=UTC" - options:为服务器连接指定额外的选项,以逗号分隔。示例:
"-c options=--statement_timeout=5000" - keepalives:指定是否启用 TCP keepalive 选项,可以是一个列表,如
[1, 3, 5]。示例:"-c keepalives=1" - keepalives_idle:设置 TCP keepalive 空闲时间(以秒为单位)。示例:
"-c keepalives_idle=120" - keepalives_interval:设置 TCP keepalive 检测间隔时间(以秒为单位)。示例:
"-c keepalives_interval=30" - keepalives_count:设置 TCP keepalive 探测失败的次数。示例:
"-c keepalives_count=5"
请注意,这些选项参数的使用和效果可能因不同的 PostgreSQL 版本、操作系统和网络环境而有所不同。您可以根据您的需求和环境进行适当的设置。
- search_path:设置数据库搜索路径,指定默认的模式(schema)。示例:
application_name:设置客户端应用程序名称,用于在服务器端标识连接的来源。
keepalives:指定是否启用 TCP keepalive 选项,可以是一个列表,如
[1, 3, 5]。keepalives_idle:设置 TCP keepalive 空闲时间(以秒为单位)。
keepalives_interval:设置 TCP keepalive 检测间隔时间(以秒为单位)。
keepalives_count:设置 TCP keepalive 探测失败的次数。
除了上述列出的参数,psycopg2.connect() 还支持其他一些高级配置选项和连接属性。具体的参数使用可以根据您的需求和 PostgreSQL 数据库的配置来进行调整。
以下是一个示例,演示如何使用一些常用参数调用 psycopg2.connect() 函数:
1 | import psycopg2 |
请注意,具体的参数值应根据您的实际数据库配置进行填写。
Chromium
下载编译chrominum
相关软件
抓包软件
- 浏览器调试工具
- fiddler
Chrome浏览器的使用
- 新建隐身窗口
network面板功能
反爬
服务器反爬的原因
爬虫占总
PV/UV比例较高,这样比较浪费钱(尤其是三月份爬虫)三月份爬虫是一个什么概念呢?每年的三月份会迎来一次爬虫高峰期,有大量的硕士在写论文的时候会选择爬取一些网站,并进行舆情分析,因为五月份交论文
公司可免费查询的资源被批量抓走,丧失竞争力,这样少赚钱
状告爬虫成功的几率小
爬虫在国内还是个擦边球,就是有可能起诉成功,也有可能完全无效,所以还是需要技术手段来做最后的保障
服务器反什么样的爬虫
十分低级应届毕业生
应届毕业生的爬虫通常简单粗暴,根本不管服务器压力,加上人数不可预测,很容易把站点弄挂
十分低级的创业小公司
现在的创业公司越来越多,也不知道是被谁忽悠的,然后大家创业了不知道干什么好,觉得大数据比较热,就开始做大数据。分析程序全写差不多了,发现自己手头没有数据,怎么办?写爬虫爬啊。于是就有了不计其数的小爬虫,出于公司生死存亡的考虑,不断爬取数据。
不小心写错了没人去停止的失控小爬虫
有些网站已经做了相应的反爬,但是爬虫程序依然孜孜不倦的爬取。什么意思呢?就是说他们根本爬不到任何数据,除了
httpcode是200以外,一切都是不对的。可是爬虫依然不停止这个很可能就是一些托管在某些服务器上的小爬虫,已经无人认领了,但依然在辛勤的工作着成型的商业对手
这个是最大的对手,他们有技术、有钱、要什么又什么,如果和你死磕,你就只能硬着头皮和他死磕
抽风的搜索引擎
大家不要以为搜索引擎都是好人,他们也有抽风的时候,而且一抽风就会导致服务器性能下降,请求量跟网络攻击每什么区别
反爬虫领域常见的一些概念
爬虫:使用任何技术手段,批量获取网站信息的一种方式,关键在于批量
反爬虫:使用任何技术手段,阻止别人批量获取自己网站信息的一种方式,关键也在于批量
误伤:在反爬虫的过程中,错误的将普通用户识别成爬虫,误伤率较高的反爬虫策略,效果再好也不能用
拦截:成功地阻止爬虫访问,这里会有拦截率的概念。通常来说,拦截率较高的反爬冲策略,误伤的可能性就月高,因此需要做权衡
资源:机器成本和人力成本的总和
反爬的三个方向
基于身份识别进行反爬
通过headers字段来反爬
headers有很多字段,这些字段都有可能被对方服务器拿过来,进行判断是否为爬虫
- 通过
headers中的User-Agent字段来反爬反爬原理:爬虫默认情况下没有
User-Agent,而是使用模块默认设置- 解决办法:请求之前添加
User-Agent即可;更好的方式是使用User-Agent池来解决(收集一堆User-Agent的方式,或者是随机生成User-Agent)
- 解决办法:请求之前添加
同一个
IP下如果有多个不同的UA,也会认定为爬虫UA池不要单独使用,要配合代理池使用UA池1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115```
- 通过`referer`字段或者其他字段来反爬
- 反爬原理:爬虫默认情况下不会带上`referer`字段,服务器端通过判断请求头发起的源头,以此判断请求是否合法
- 解决办法:添加`referer`字段
- 通过`cookie`来反爬
- 反爬原因:通过检查`cookie`来查看发起请求的用户是否具备相应权限,以此来进行反爬
- 解决方案:进行模拟登陆,成功获取`cookie`之后再进行数据爬取
#### 通过请求参数来反爬
> 请求参数的获取方法有很多种,向服务器发送请求,很多时候需要携带请求参数,通常服务器端可以通过检查请求参数是否正确来判断是否为爬虫
- 通过从`html`静态文件中获取请求参数
- 反爬原因:通过增加获取请求参数的难度进行反爬
- 解决方案:仔细分析抓包得到的每一个包,搞清楚请求之间的联系
- 通过发送请求获取新的请求数据
- 反爬原因:通过增加获取请求参数的难度进行反爬
- 解决方案:仔细分析抓包得到的每一个包,搞清楚请求之间的联系
- 通过`js`生成请求参数
- 反爬原因:`js`生成了请求参数
- 解决方案:分析`js`,观察加密的实现过程,通过`js2py`获取`js`的执行结果,或者使用`selenium`来实现
- 通过验证码来反爬
- 反爬原因:对方服务器通过弹出验证码,强制用户浏览行为
- 解决方案:打码平台或者机器学习的方法识别验证码,其中打码平台廉价易用,更值得推荐
### 基于爬虫行为进行反爬
#### 基于请求频率或总请求数量
> 爬虫的行为与普通用户有着明显的区别,爬虫的请求频率与请求次数要远高于普通用户
- 通过请求`ip`/账号单位时间内总请求数量进行反爬
- 反爬原理:正常浏览器请求网站,速度不会太快,同一个`ip`/账号大量请求了对方服务器,有更大的可能性会被识别成爬虫
- 解决办法:对应的通过购买质量的`ip`的方式能够解决这个问题/购买多个账号
- 通过同一`ip`/账号请求之间的间隔进行反爬
- 反爬原理:正常人操作浏览器浏览网站,请求之间的时间间隔是随机的,而爬虫前后两个请求之间的时间间隔通常比较固定,同时时间间隔较短,因此可以用来反爬
- 解决办法:请求之间进行随机等待,模式真实用户操作,在添加时间间隔后,为了能够告诉获取数据,尽量使用代理池,如果是账号,则将账号请求之间设置随机休眠
- 通过对请求`ip`/账号之间设置阈值进行反爬
- 反爬原理:正常的浏览行为,其一天的请求次数是有限的,通常超过某一个值,服务器就会拒绝响应
- 解决办法:对应的通过购买高质量`ip`/账号,同时设置请求间随机休眠
#### 根据爬取行为进行反爬
- 通过js实现跳转来反爬
- 反爬原理:js实现页面跳转,无法在源码中获取下一页url
- 解决办法:多次抓把获取url,分析规律
- 通过蜜罐(陷阱)获取爬虫`ip`(获取代理`ip`),进行反爬
- 反爬原理:在爬虫获取链接进行请求的过程中,爬虫会根据正则、`xpath`、`css`等方式进行后续链接的提取,此时服务器端可以设置一个陷阱`url`,会被提取规则获取,但是正常用户无法获取,这样就能有效的区分爬虫和正常用户
- 解决办法:完成爬虫的编写之后,使用代理批量爬取测试\仔细分析响应内容的结构,找出页面中存在的陷阱
- 通过假数据反爬
- 反爬原理:向返回的响应中添加假数据污染数据库,通常假数据不会被正常用户看到
- 解决办法:长期进行,核对数据库中数据同实际页面中数据对应情况,如果存在问题,仔细分析响应内容
- 阻塞任务队列
- 反爬原理:通过生成大量垃圾`url`,从而阻塞任务队列,降低爬虫的实际工作效率
- 解决办法:观察运行过程中请求响应状态,仔细分析源码获取垃圾`url`规则,对`url`进行过滤
- 阻塞网络IO
- 反爬原理:发送请求获取响应过程,实际上就下载过程,在任务队列中混入一个大文件的`url`,当爬虫在进行该请求时,将会占用网络IO,如果是有多线程则会占用线程
- 解决办法:观察爬虫运行状态、多线程对请求线程计时
- 运维平台综合审计
- 反爬原理:通过运维平台进行综合管理,通常采用复合型反爬虫策略,多种手段同时使用
- 解决办法:仔细观察分析,长期运行测试目标网站,检查数据采集速度,多方面处理
### 基于数据加密进行反爬
对响应中含有的数据进行特殊化处理
- `css`数据偏移
- 样例:去哪儿网机票价格字段:https://www.qunar.com/
- 反爬思路:源数据不是真正数据,需要通过css位移才能产生真正数据
- 自定义字体
- 解决办法:切换到手机版,或解析字体文件进行翻译。
- 样例:猫眼电影票房字段:https://www.maoyan.com/films/1433776
- 数据加密,通过js动态生成数据
- 反爬原理:通过js动态生成
- 解决思路:解析关键js,获得数据生成流程,模拟生成数据
- 数据图片化
- 样例:58同城短租
- 反爬原理:数据以图片格式提供
- 解决思路:通过使用图片解析引擎从图片中解析数据
- 特殊编码格式
- 反爬原理:不使用默认编码格式,在获取响应之后通过爬虫使用`utf-8`进行解码,此时解码结果将会是乱码或者报错
- 解决思路:根据源码进行多格式解码
- 等等
#### `JS`解析
> 了解定位js的方法
>
> 了解添加断点观察js执行过程的方法
>
> 模拟加密步骤:
>
> - js2py、pyv8、execjs、splash等其他模块
> - 纯python实现
如人人网登陆的password字段,直接搜是搜不到的,是一个已经被js加密的过程量。有些其他字段也是js生成,需要**定位js**的具体位置
#### hashlib的使用
```python
import hashlib
data = 'python'
# 创建hash对象
md5 = hashlib.md5()
# 向hash对象中添加需要做hash运算的字符串
md5.update(data.encode())
# 获取字符串的hash值
result = md5.hexdigest()
print(result)
爬虫项目变大后,url数量从百千,上升到万亿,如何去重呢?
- 小容量存
python集合 - 存
redis数据库(url做完hash存,可以省容量) - 布隆过滤器(更复杂点的hash)
现在新闻都是你抄我我抄你,需要对文本内容去重
- 编辑距离算法
- simhash算法
验证码处理
- 了解验证码的相关知识
- 掌握图片识别引擎的使用
- 了解常见的打码平台
- 掌握通过打码平台处理验证码的方法
图片验证码
什么是图片验证码
- 验证码(
CAPTCHA)是Completely Automated Public Turing test to tell Computers and Humans Apart(全自动区分计算机和人类的图灵测试)的缩写,是一种区分用户是计算机还是人的公共全自动程序
验证码的作用
- 防止恶意破解密码、刷票、论坛灌水、刷页。有效防止某个黑客对某一个特定注册用户用特定程序暴力破解方式进行不断的登陆尝试,实际上使用验证码是现在很多网站通行的方式(比如招商银行的网上个人银行,百度社区),我们利用比较简易的方式实现了这个功能,虽然登陆麻烦一点,但是对网友的密码安全来说,这个功能还是很有必要,也很重要
图片验证码在爬虫中的使用场景
- 注册
- 登陆
- 频繁发送请求时,服务器弹出验证码进行验证
图片验证码的处理方案
- 手动输入(input),这种方法仅限于登陆一次就可持续使用的情况
- 图像识别引擎解析,使用光学识别引擎处理图片中的数据,目前常用于图片数据提取,较少用于验证码处理
- 打码平台,爬虫常用的验证码解决方案(背后是大量人工)
- 深度学习
图片识别引擎
OCR(Optical Character Recongnition),是指使用扫描仪或数码相机对文本资料进行扫描成图像文件,然后对图像文件进行分析处理,自动识别获取文字信息及版面信息的软件
什么是tesseract
- 一款由
HP实验室开发,由Google维护的开源OCR引擎,特点是开源、免费、支持多语言、多平台
1.图片识别引擎环境的安装
1 | # windows |
2.python库的安装
1 | # PIL用于打开图片文件 |
3.图片识别引擎的使用
终端输入:tesseract image.png result
结果:最后的符号还是有问题的
1 | # 通过pytesseract模块的image_to_string方法,就能将打开的图片文件中的数据提取成字符串数据,具体如下: |
图像识别引擎的使用扩展
tesseract简单使用与训练:
其他ocr平台
1 | 微软Azure图像识别 |
打码平台
百度搜一下,会使用接口文档
常见验证码种类
url地址不变,验证码不变
- 这是验证码非常简单的一种类型,对应的只需要获取验证码的地址,然后请求,通过打码平台识别即可
url地址不变,验证码变化
这种验证码的类型是更加常见的一种类型,对于这种验证码,需要思考:
在登陆的过程中,假设我输入的验证码是对的,对方服务器如何判断当前我输入的验证码就是先是在我屏幕上的验证码,而不是其他的验证码呢?
在获取网页的时候,请求验证码,以及提交验证码的时候,对方服务器肯定通过了某种手段,验证我之前获取的验证码和最后提交的验证码是同一个验证码,那这个手段是什么呢?
很明显,就是通过
cookie来实现的,所以对应的,在请求页面,请求验证码,提交验证码的时候,需要保证cookie的一致性,对此可以使用request.session来解决或者使用
selenium对指定区域截屏,然后当作图片处理
常见网站反爬措施
百度
百度翻译
token存在了请求的index.html中
百度贴吧
返回的
index.html,对实际数据加了注释使用低级浏览器UA
将注释字符串替换掉,再用
xpath提取1
data = data.decode().replace("<!--", "").replace("-->", "")
自动化登陆
加密算法
对称加密算法
当谈论对称加密算法时,我们在加密和解密过程中使用相同的密钥。这种密钥在数据的发送和接收之间共享,因此对于确保安全性,密钥的管理和保护非常关键。下面是对称加密算法的详细介绍:
工作原理:
对称加密算法使用相同的密钥来执行加密和解密操作。在加密过程中,明文(原始数据)通过算法和密钥进行处理,生成密文(加密后的数据)。在解密时,相同的密钥被用于反转加密操作,从而还原原始数据。
特点:
- 速度快:相比非对称加密算法,对称加密算法通常执行速度更快,因为它们涉及的数学操作较为简单。
- 适用于大数据量:对称加密适用于加密大量数据,因为其速度更快,不会造成明显的性能问题。
- 密钥管理挑战:由于相同的密钥用于加密和解密,密钥的传输和管理变得关键。安全地共享密钥以防止未经授权的访问和篡改是挑战之一。
常见的对称加密算法:
- AES(Advanced Encryption Standard):这是一种最常用的对称加密算法之一。AES操作块大小为128位,密钥长度可以是128、192或256位。它被广泛用于数据保护、网络通信和其他领域,因为它的安全性和性能相对较好。
- DES(Data Encryption Standard):DES是一种较旧的对称加密算法,使用56位密钥和64位的数据块大小。然而,由于其较短的密钥长度,DES在当前的计算环境下已经不再安全。
- 3DES(Triple Data Encryption Standard):为了增强DES的安全性,3DES使用了多次DES加密过程,提供更大的密钥空间和更高的安全性。然而,由于其性能相对较慢,现在更常使用更现代的加密算法。
安全性考虑:
虽然对称加密算法提供了速度和效率,但它们在密钥管理方面存在挑战。确保密钥的安全性、保护免受未经授权的访问以及密钥的轮换都是关键问题。此外,对称加密算法在密钥交换方面存在难题,因为发送方和接收方都需要在数据传输之前约定密钥。
在某些情况下,对称加密可以与非对称加密结合使用,以解决密钥分发和管理的问题。例如,可以使用非对称加密来安全地传输对称加密所需的密钥,从而在数据传输期间确保更高的安全性。
总之,对称加密算法在很多情况下都是一个有效的数据保护方法,但在选择加密算法和实施方案时,必须考虑密钥管理、安全性需求和性能要求。
非对称加密算法
非对称加密使用一对密钥:公钥和私钥。公钥用于加密数据,而私钥用于解密数据。这意味着任何人都可以使用公钥加密数据,但只有持有相应私钥的接收方才能解密数据。非对称加密在密钥交换方面更加安全,因为私钥不需要被共享。
常见的非对称加密算法包括:
- RSA(Rivest-Shamir-Adleman):一种常用的非对称加密算法,广泛用于数字签名和数据加密。
- ECC(Elliptic Curve Cryptography):基于椭圆曲线数学的加密算法,提供与传统方法相同安全级别的加密,但使用更短的密钥。
消息摘要算法(哈希函数)
消息摘要算法也被称为哈希函数,它将任意长度的输入数据转换为固定长度的输出(哈希值)。消息摘要通常用于验证数据的完整性,因为即使输入数据发生微小的变化,生成的哈希值也会完全不同。这可以防止未经授权的数据篡改。
常见的消息摘要算法包括:
- MD5:一种较为旧的消息摘要算法,但由于存在漏洞,已不再推荐用于安全性要求较高的应用。
- SHA-1(Secure Hash Algorithm 1):虽然仍然广泛使用,但已经出现碰撞漏洞,逐渐不再被视为安全的选项。
- SHA-256:SHA-2系列中的一员,提供更高的安全性和强大的碰撞抵抗性。
数字签名算法
数字签名是确保数据的身份验证、完整性和不可抵赖性的方式。它使用私钥对数据进行签名,而公钥用于验证签名。如果签名是有效的,那么可以确定数据未被篡改且来自特定的签名者。
常见的数字签名算法通常与非对称加密算法结合使用,例如:
- RSA数字签名:使用RSA算法生成数字签名,提供数据的认证和完整性。
魔改算法
jsvmp加密
- 知乎、携程、抖音、巨量
混淆
ob混淆
前端资源打包器(webpack)
jsdom
oo混淆
发起程序的堆栈调用中,变量名有以下划线开头的,类似16进制的变量名,如:https://bz.zzzmh.cn/index
数组混淆
变量名混淆
jj混淆
web逆向
在Python爬虫领域,网站为了防止被爬虫抓取或者保护其数据,采取的一系列技术手段,使得爬虫难以直接解析和获取数据。这些技术手段可以使得网页的结构、内容或者请求方式变得复杂,从而增加爬取的难度。以下是一些常见的逆向混淆技术:
- 动态加载数据: 很多网站使用JavaScript来动态加载数据,这意味着网页的初始HTML源代码中并不包含完整的数据,而是通过异步请求获取数据并渲染到页面上。这对于传统的静态爬虫来说会变得更加困难,需要使用工具如Selenium来模拟浏览器行为。
- 验证码: 网站为了确认用户是人而不是爬虫,会在表单提交或者登录时要求用户输入验证码。这可以有效地阻止大多数自动化爬虫。
- 反爬虫机制: 网站会监测频繁的请求和用户行为模式,如果怀疑某个IP地址是爬虫,就会采取措施限制其访问,如IP封禁或者延时响应。为了规避这种反爬虫机制,爬虫可能需要使用代理IP、用户代理、随机延时等手段。
- User-Agent伪装: 爬虫在发送HTTP请求时,可以伪装成浏览器发送请求,从而绕过一些简单的反爬虫机制。但一些网站可能会检测User-Agent是否合法,如果怀疑是爬虫,仍然会采取限制措施。
- 数据混淆: 网站可能对数据进行编码、加密或者其他形式的混淆,使其在页面源代码中不易被直接识别。这要求爬虫解码或解密这些数据才能得到有用信息。
- 页面结构变化: 为了防止爬虫基于HTML标签解析页面,网站可能会不断调整页面结构、类名、ID等元素的命名,使得爬虫需要频繁更新解析逻辑。
- 动态参数: 有些网站使用动态生成的参数来构建请求,这些参数可能包括时间戳、随机字符串等。爬虫需要先解析页面获取这些参数,然后再构建请求。
- JS逆向工程: 部分网站在页面中嵌入复杂的JavaScript代码,用于生成数据或者动态操作。爬虫需要分析这些代码,模拟其行为以获取数据。
要克服这些逆向混淆技术,爬虫开发者可能需要使用反反爬虫技术,如使用Headless浏览器、动态生成User-Agent、使用代理池、破解验证码等。然而,请注意,在进行爬虫活动时,应遵守网站的robots.txt文件中的规定,并遵循法律和道德规范。不当的爬虫行为可能会对网站的正常运行造成影响,并可能触犯法律。
- 了解逆向
- 数据加密
- 请求参数加密
- 表单加密
- 能够扣
js代码 - 通过
python改写js代码
了解逆向
F12或者鼠标右键打开控制台,主要了解的由四个板块
元素
被渲染的数据
- 静态数据
- 动态数据
一开始对数据结构不了解的情况,如何定位到自己想找的数据:
可以使用搜索的方式,但数据是加密的话,是得不到搜索结果的
这个网站的返回数据,就做了加密:交易列表 - 福建省公共资源交易电子公共服务平台 (fujian.gov.cn)
控制台
源代码
htmljscss- 字体
网络
- 抓包
响应数据解密定位
服务器返回了加密的数据,如何进行解密?
web端一般由js执行解密操作,需要在成千上万行的js代码中,精准的定位到所需要的解密方法
解密思路
- 先观察
- 再定位
- 搜索大法
整体观察
1.先确定js代码是否存在混淆、是否存在加密
混淆
打开
发起程序,观察调用堆栈的变量名,如果是可读的,则一般不存在混淆,如:http://www.whggzy.com/PoliciesAndRegulations/index.html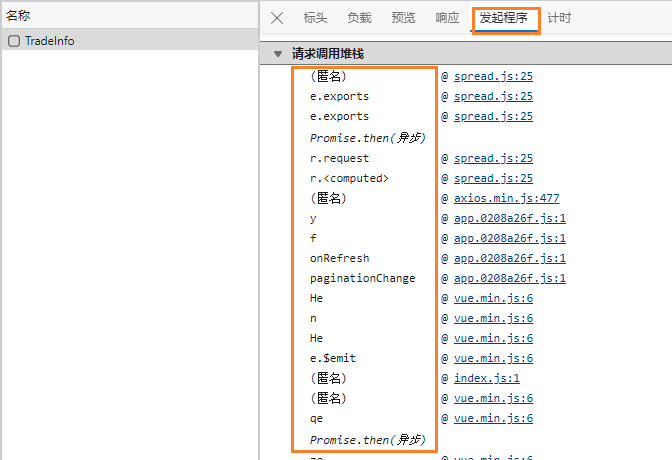
如果存在混淆,以下是
ob混淆,会出现类似于十六进制的,下划线开头的变量名:https://bz.zzzmh.cn/index
加密
eval函数:可以执行js逻辑
定位
2.定位加密或者解密方法的位置
先观察有没有关键字,比如接口中有一个字段
data,但有个问题,这类关键字是非常宽泛的, 直接搜索这类的关键字,是没有意义的
搜索标准解密算法的方法名
交易列表 - 福建省公共资源交易电子公共服务平台 (fujian.gov.cn)
对上述网站接口,进行请求后得到的响应数据,如下:

可以搜索解密方法的关键字:decrypt(,带上括号,表示调用。
然后在找到的文件中,尝试都打上断点

把找到的方法整体,复制到新的js文件中
1 | function b(t) { |
注意:并不需要完全看懂js代码,明白整体的运行逻辑即可
先取消监视之前的断点,在这个方法的return返回值前,单独添加一个断点,然后在控制台打印

是明文数据,说明我们b方法是一个解密方法
通过打断点的方式,我们拿到一份t,放到node里运行
1 | // 样例不放完整的data了,太长了 |
控制台会报各种未定义,很正常。接下来需要把这些环境变量给补充完整:
1 | var e = h.a.enc.Utf8.parse(r["e"]), |
h是以实例对象的方式调用的,控制台中逐个打印输出。通过观察代码中的其他地方,h.a应该是比较有用的信息
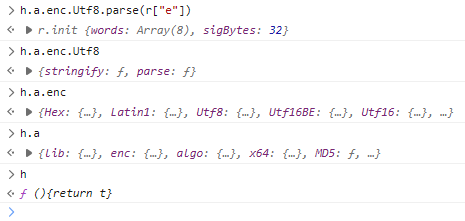
此时我们是不清楚,该方法是不是标准加密算法的,我们可以在node中,导入js的标准算法库进行验证
1 |
|
结果是明文数据。反过来再看,这段数据采用了CBC的加密模式,Pkcs7填充方法的AES加密
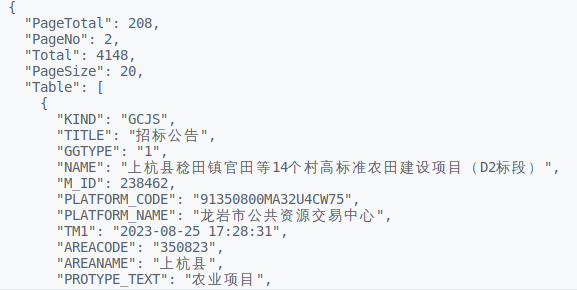
接下来使用pyexecjs来构建爬虫
1 | pip install pyexecjs -i https://pypi.tuna.tsinghua.edu.cn/simple |
注意需要更新下请求
1 | import requests |
接下来就是分页,数据入库。
搜索返回数据中的关键字
带有关键字如何处理
直接搜索关键字,注意不能很宽泛。
外部一定需要有一个解密的方法,不可以是内置的,如x_cccc(密文),一般不会是x_cccc(密文).name这种形式
样例网站:企名片-科技创新服务平台 (qimingpian.com)
数据是密文的,而且包含关键字encrypt_data
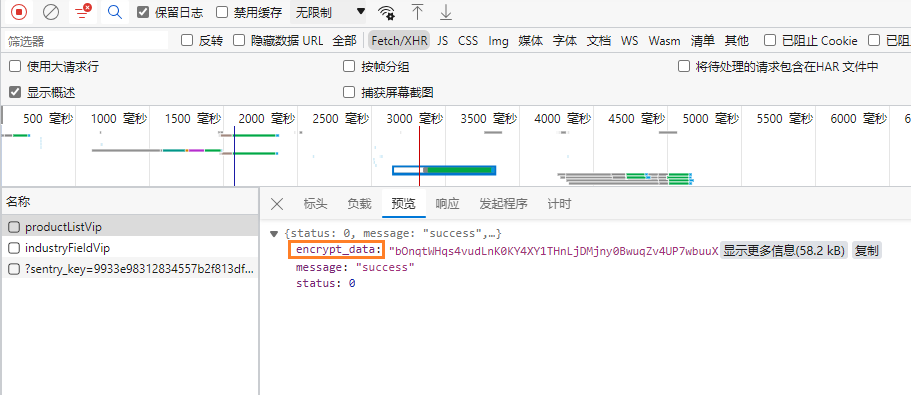
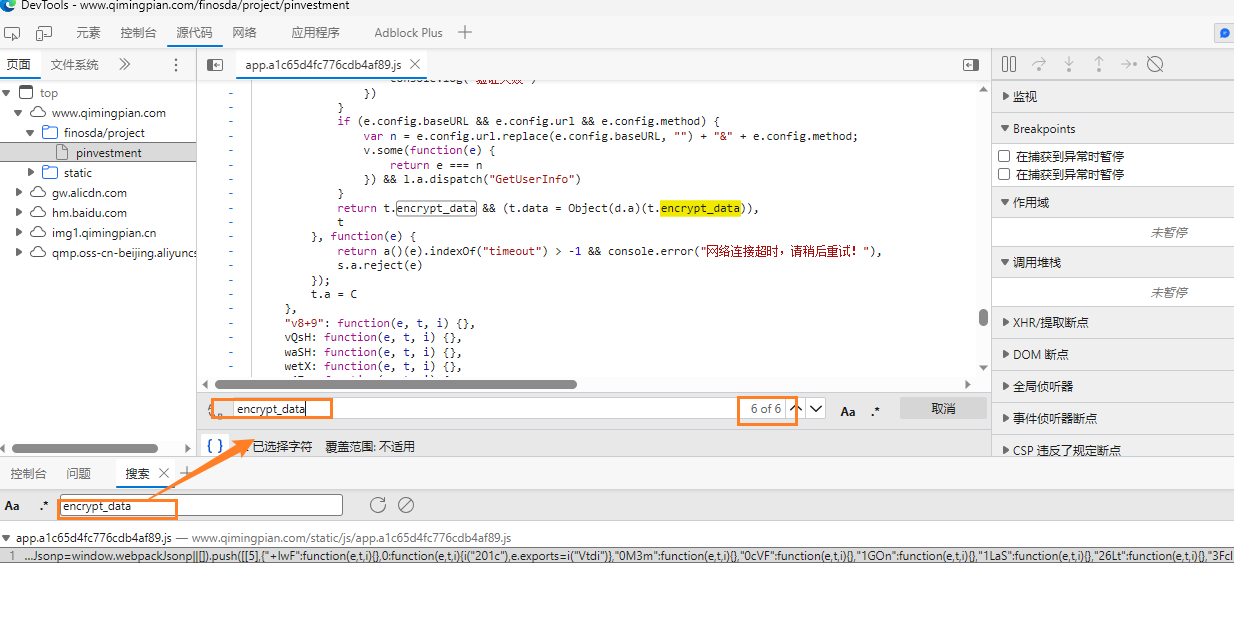
有6个结果,前4个都是取imgUrl的值,应该不是。
应该是后面的那个,打双层断点观察(先打外层断点,再打内层断点)

让代码走到中间的断点,然后打印输出,得到明文数据

这些都是很简单的,难度较高的有瑞数、极验四代等等
开始扣js代码 ,在控制台打印Object(d.a),然后点击结果跳转,拿到s方法
1 |
|
然后node中执行,根据报错补环境,缺哪个就在哪边打断点,然后打印输出,再点击跳转。
那有没有更好的方式呢?
比如现在要补充o方法,添加断点后不用点击跳转,控制台直接输入o.toString(),拿到函数内容

继续执行,提示a未定义,找a,还要补一下f、l
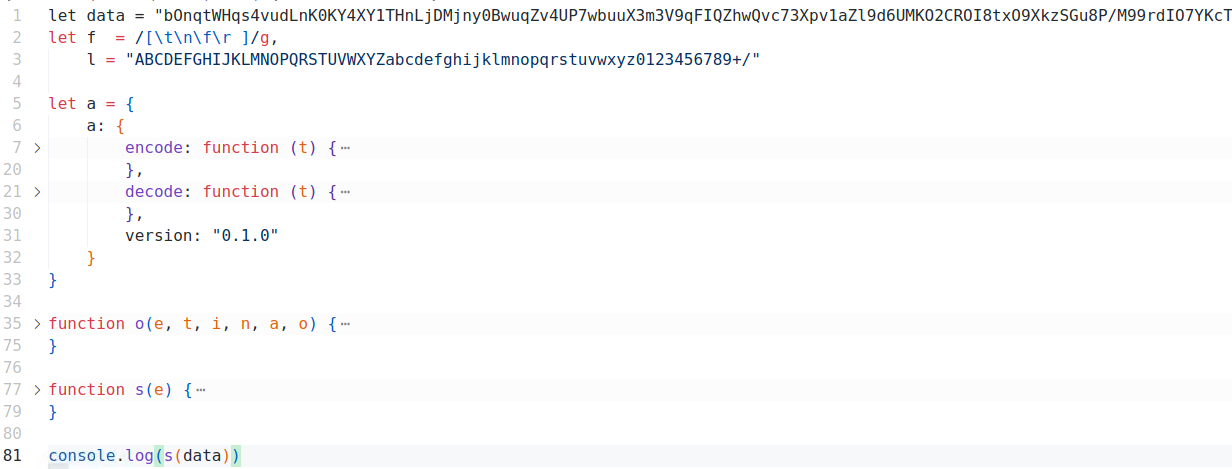
得到明文数据

和python进行交互
1 | import requests |
没有搜索依据或搜索无结果
现在网站的构建方式,基本都是前后端分离,以json数据格式进行交互,前端代码中一般会有JSON.parse()这种数据类型转换的代码。并且极有可能会包含一个自定义的解密方法或密文,类似JSON.parse(decode(data)),如果是内置方法,则可以跳过。
弊端,很多的文件都会包含JSON.parse,所以一般会结合XHR断点使用
进入接口的主文件后,再搜索JSON.parse
以犀牛数据为例:https://www.xiniudata.com/report
进入具体文件后搜索:
像下面的,就肯定不是了

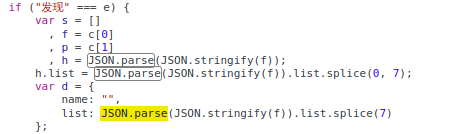
找到像是解密的地方,打上断点:

控制台输出JSON.parse(y),得到明文数据
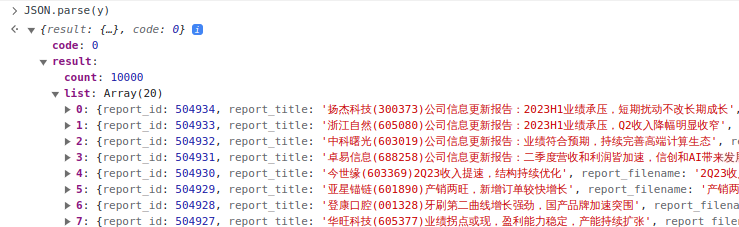
此时扣js代码:
1 | var d = Object(c.a)(l) |
接下来的流程和上述一致,细节不再重复,留作作业。
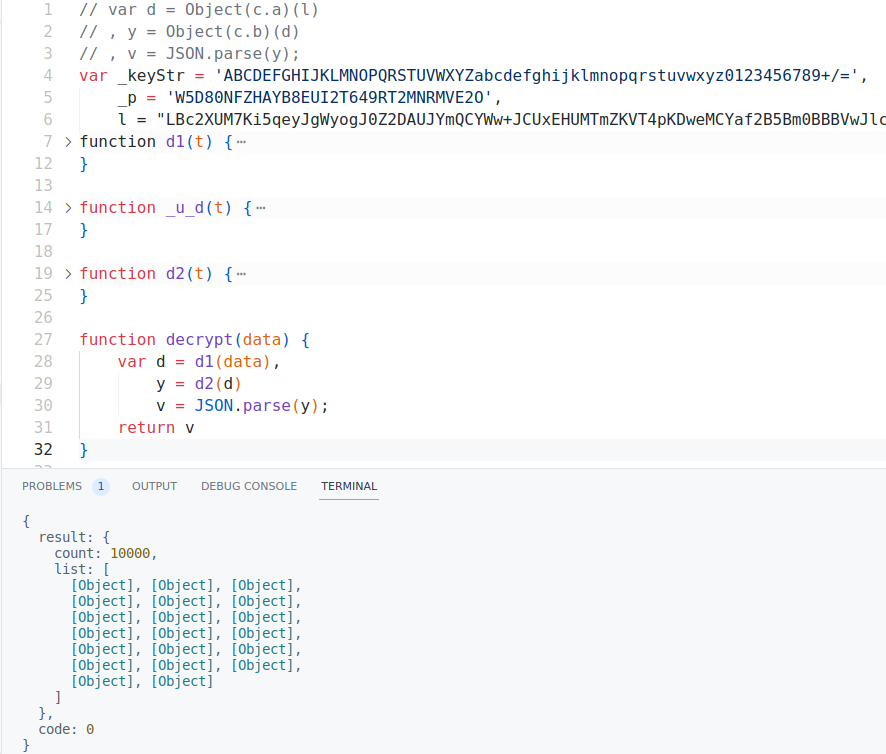
1 | import requests |
拿到明文数据:

标准算法解密
搜索
decrpt(- 一般是实例对象中的实例方法调用,而不会是类的方法调用
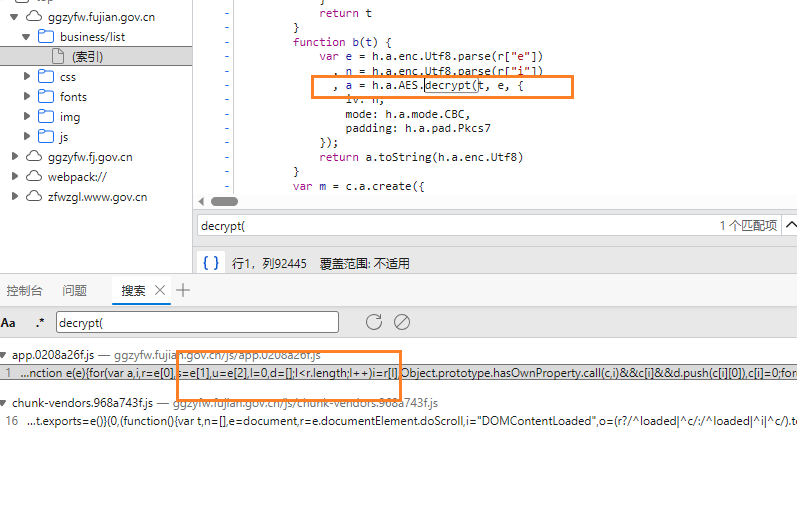
搜索接口关键字
后端
ajax渲染(json数据渲染网站:JSON.parse(),数据类型转变的方法),无混淆js
请求数据加密定位
加密是模拟加密方法,以及找到对应明文(被加密的内容)
- 请求头参数签名加密
- 请求体加密
cookie加密- 请求参数加密
请求头含加密字段
案例:
F12后,点击分页没有接口数据,因为是一次性加载的全部数据

重新刷新网站或者在界面上,点击筛选条件,可以知道到请求数据是哪一个接口
从请求头中,可以看出是有请求头加密的
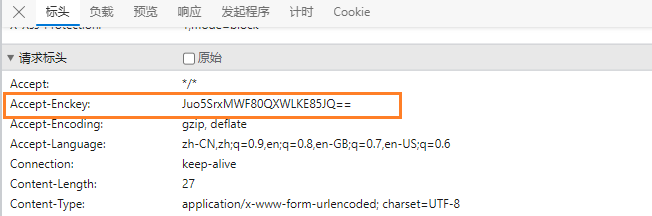
遇到请求头加密,用左边的放大镜(只搜索response的数据,不会搜索请求的静态资源)先搜索该加密字符串,看是否是由服务器返回在了其他响应中,都不到的话,说明不在响应接口数据里。
另外,同数据解密定位类似,这个也是可以搜索关键字的,这里的关键字是Accept-EncKey,也可以搜索请求发送的路径,进行文件定位。因为前端肯定要加上这个路径的接口数据进行请求的
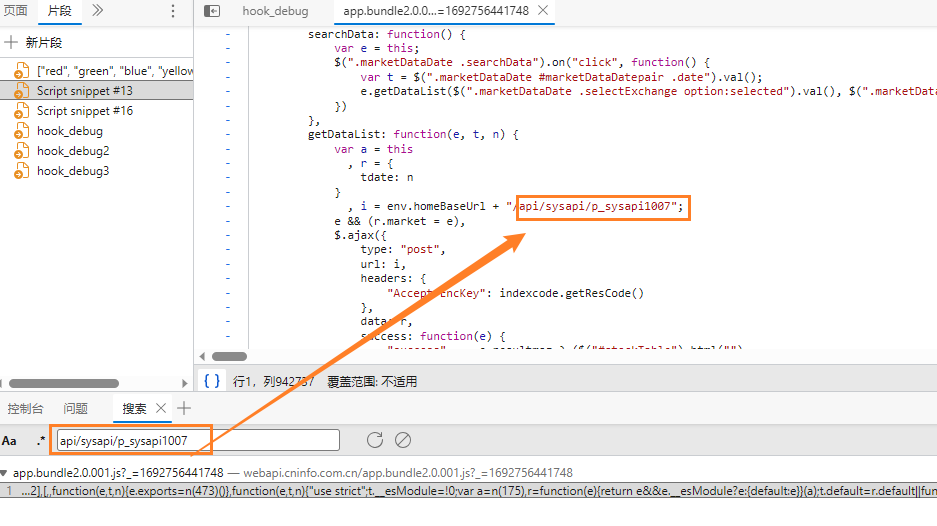
下面就看到了ajax请求构造参数的代码:
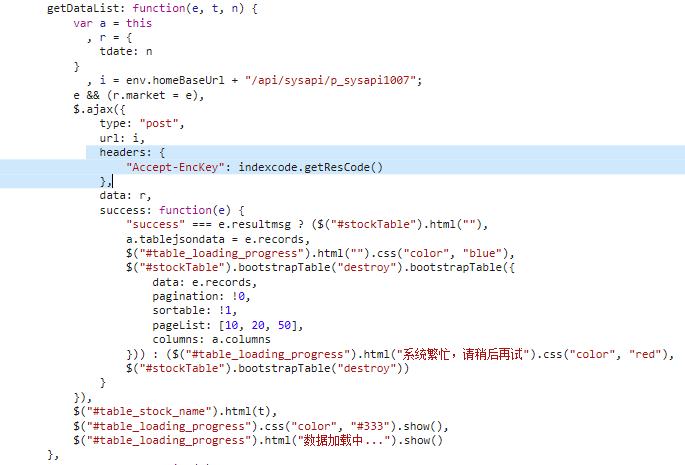
打断点,重新请求。发现indexcode.getResCode()的调用结果,每次都是不一样的
另外,我们无法直接在控制台打印,从而定位函数的具体位置。只能调试堆栈,点击下一步,会发现getResCode是一段混淆代码(数组混淆)
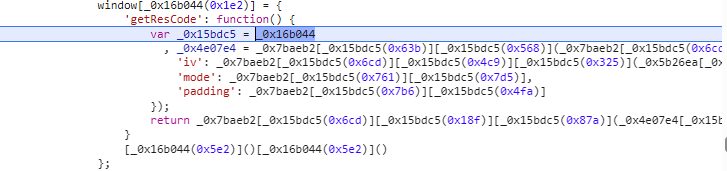
给谁都不认识,接下来将几个思路
核心加密的方法,应该是return后面
1 | let getResCode = function () { |
思路一:还原,首先确定变量:
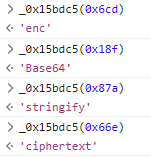
1 |
|
思路二:也可以不做还原,做全局代码扣取。但是要补环境。
类似数据解密时的步环境,在node中运行,缺啥补啥
如果遇到标准库算法,导包并进行全局替换
然后执行,一次次的进行环境补充
技巧:有些函数调用不一定要补函数定义,因为不断的补定义,可能会出现一环套一环的情况,可以试着直接补函数的返回结果(虽然有可能是变化的)
此例中,补环境补到最后,发现还要补浏览器环境:
思路三:也可以一个一个扣代码。
思路四:搜索关键字
首页数据定位到接口后,可以直接搜索关键字sign:
请求参数为进制数据
案例:

请求表单在请求之前生成的。且没有关键字,可以复制url中的路径,进行XHR断点提取

然后页面上进行标签切换,让它发请求。
等到进入断点后,我们可以继续让程序往下执行两步(自己调试),就可以看到该次请求的所携带的配置参数
找到data,可以点击查看:

可以 看到0x应该是加密成了16进制
但是肯定是通过明文数据,经过加密方法处理后,才得到的加密数据
先找到构造明文数据的代码位置
在请求发送的断点处,往上走,跳出当前函数。

在此过程中,不断的去看,找到作用域里有
XMLHttpRequest请求对象,然后看代码。可以看到构造请求的参数的具体位置了:
此时再往上走一步,看作用域:

看
config字段,里面有一个headers字段,去看里面的请求参数还是不是密文(这里还是密文)不断的继续向上走(可能需要很久很久),直到找到包含明文的变量
想要更快的定位,可以使用
ajax库中的请求拦截器,来实现构造参数代码定位在定位到构造的密文请求对象后,往上走直至找到请求对象
在控制台分别打印,找到拦截器
interceptors
其实就是
axios的拦截器
我们需要的其实是请求拦截器:

这样就可以快速定位请求发送之前的位置,点击跳转后,在开头打一个断点,并在结尾处也打一个断点,然后进行调试(记得删除其他断点,如
XHR断点),然后执行直到结束位置,再看作用域,此时的位置,请求参数是明文的:
同时返回值
r,是处理后的密文:
请求参数是在请求拦截器里进行加密的
下一步干嘛,定位到明文变密文的具体那一行代码
样例中就是要找
r['data'],可以在控制台里打印输出,也可以调试代码,一个一个看包含r的变量,看哪里有取值操作
然后在开始和结束,打断点

会发现由明文数据变成了进制数据
同时,我们也就获取了加密逻辑:

再找到加密方法(如上,已找到)
进行js代码构造,扣代码

找到该方法的源代码,复制到js文件中,注意变量名可能存在特殊符号
然后执行js,根据报错信息,不断补未定义的变量。(如果能看懂js代码,可以进行一定的改写,让其不必引用无用的变量)
补未定义变量时有些时候通过跳转,会跳不进去
现在前端的代码,大部分都是通过
webpack等打包后的的模块化代码,在做跳转时跳不进去(追踪不到栈信息),可以在全局搜索未定义的变量或方法
还需要复制下webpack生成的模块代码(会很长),在补变量时,有些变量是局部变量,可以找到全局的一样的变量去替换(如果有)
如果有的变量是局部变量,可以定义全局变量,在函数里用该全局变量接收函数内的局部变量,然后改写用到该变量的地方
如果通过python去用到进制数据,拿到数据后,需要转为字节

cookie加密
不同于接口请求,cookie是属于dom的。
静态cookie
二次返回
- 第一次请求不携带
cookie,返回的可能是html中包含js代码,也可以直接返回js代码。此时js环境没有启动 - 然后根据返回的
js代码,生成cookie,拿着cookie进行第二次实际请求。相当于同一个接口做了两次响应
https://www.ontariogenomics.ca/news-events/
能被看到的,就可以被叫做纯静态数据,可以通过xpath、正则等直接提取到
我们清除日志,清除cookie,重新发送请求,会发现请求了两次,并且第一次的请求头是没有cookie的
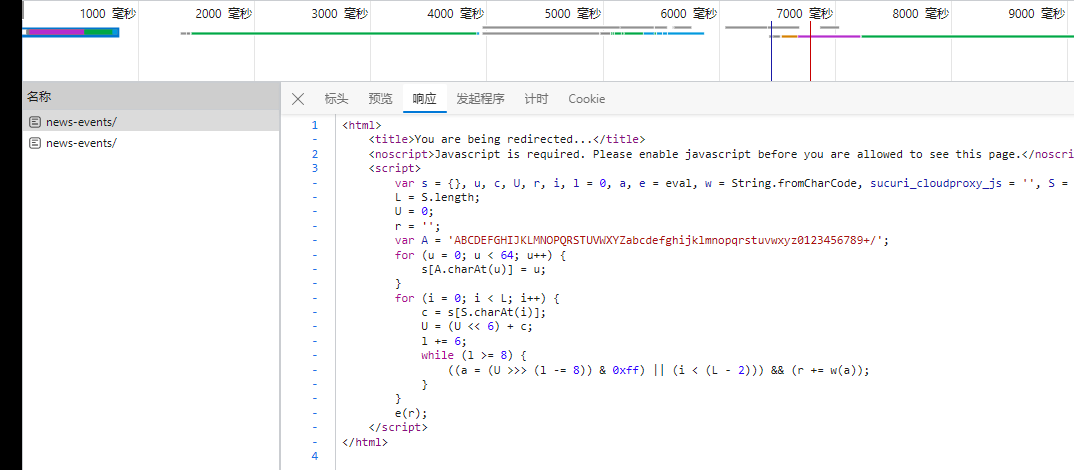
拿到第一次请求返回的js,开始补环境
1 | var s = {}, u, c, U, r, i, l = 0, a, e = eval, w = String.fromCharCode, sucuri_cloudproxy_js = '', S = 'Yz0nbU8yJy5jaGFyQXQoMikrIjdzdSIuc2xpY2UoMCwxKSArICIiICsiM3UiLmNoYXJBdCgwKSArICIiICtTdHJpbmcuZnJvbUNoYXJDb2RlKDB4MzIpICsgICcnICsnUjEnLnNsaWNlKDEsMikrU3RyaW5nLmZyb21DaGFyQ29kZSg0OSkgKyAgJycgKycnKyc7dTdhJy5zdWJzdHIoMywgMSkgKyAnJyArIApTdHJpbmcuZnJvbUNoYXJDb2RlKDU0KSArIFN0cmluZy5mcm9tQ2hhckNvZGUoNTYpICsgICcnICsgCiJlc3UiLnNsaWNlKDAsMSkgKyAiMXAiLmNoYXJBdCgwKSArICcxNycuc2xpY2UoMSwyKSsiIiArImEiLnNsaWNlKDAsMSkgKyAneTk1Jy5jaGFyQXQoMikrICcnICsgCiJlbyIuY2hhckF0KDApICsgU3RyaW5nLmZyb21DaGFyQ29kZSg1MCkgKyAiZSIgKyAiZCIgKyAgJycgK1N0cmluZy5mcm9tQ2hhckNvZGUoNTcpICsgIjAiICsgIjMiLnNsaWNlKDAsMSkgKyAiZSIgKyAgJycgKycnKyI5IiArICdqSjAnLmNoYXJBdCgyKSsgJycgKycnKyc5clQ0Jy5zdWJzdHIoMywgMSkgKyAnJyArIAondkcxJy5jaGFyQXQoMikrICcnICsgClN0cmluZy5mcm9tQ2hhckNvZGUoOTgpICsgImMiICsgIjYiLnNsaWNlKDAsMSkgKyAiNnN1Y3VyIi5jaGFyQXQoMCkrImIiLnNsaWNlKDAsMSkgKyAnMCcgKyAgIiIgKycnO2RvY3VtZW50LmNvb2tpZT0ncycrJ3N1Jy5jaGFyQXQoMSkrJ2MnKyd1c3VjJy5jaGFyQXQoMCkrICdyJysnJysnc3VjdWknLmNoYXJBdCg0KSsgJ3N1Y3VyXycuY2hhckF0KDUpICsgJ2NzdScuY2hhckF0KDApICsnc3VjdXJsJy5jaGFyQXQoNSkgKyAnbycrJycrJ3UnKydkJysncHN1YycuY2hhckF0KDApKyAncnN1Jy5jaGFyQXQoMCkgKydvc3VjdScuY2hhckF0KDApICArJ3gnKycnKydzdWN1eScuY2hhckF0KDQpKyAnXycrJ3UnKydzdWN1cnUnLmNoYXJBdCg1KSArICdpJysnJysnZHN1Jy5jaGFyQXQoMCkgKydfc3VjdScuY2hhckF0KDApICArJzEnLmNoYXJBdCgwKSsnNicrJzMnKydhJysnNCcrJzInKydjJysnczUnLmNoYXJBdCgxKSsnc3VjdWUnLmNoYXJBdCg0KSsgIj0iICsgYyArICc7cGF0aD0vO21heC1hZ2U9ODY0MDAnOyBsb2NhdGlvbi5yZWxvYWQoKTs='; |
运行提示dom对象未定义,dom是浏览器环境,一般来说不是那么容易搞定的。但这里的未定义不是说dom.xxx未定义,我们可以尝试设置空对象:

demo.js
1 | function run() { |
main.py
1 | import requests |
注意,不同的机器返回的js会不一样,如果加了cookie之后,仍然拿不到页面数据,就拿报错页面返回的js再跑一次
5s盾
动态生成cookie
每次访问一个页面,都会生成新的cookie
如:中国海关、药监局、中国工商、中国公安、信息化政务部等等gov网站
这种情况是必须要逆向的
时效性cookie
一定的时间内有效,会过期
如:boss直聘、51job
网站需要登陆
如果没有的登陆,服务器根本不会返回数据
如:知乎、飞瓜数据、巨量云图等分析平台,都是要做账号登陆的,只有登陆后才能看到数据。
需要逆向登陆,并且登陆后返回的cookie中,一般都会有字段加密
阿里系acw_v2
两次加载
加速乐
一个页面三次请求
- 初始化请求,获取一段
js代码(生成cookie的值),js - 第二次请求,第一次生成的
cookie载入,请求一段js代码,混淆js - 第三次请求,携带上次生成的
cookie
瑞数
4代
5代
5.5代
3月份5.5代,药监局的一个单字,5k
6代
现在药监局是6代
akamai
1.75版本
2.0版本
3.0版本
webpack加密
HOOK
头部请求参数
绕过网站反debugger
样例网站:首页-产业政策大数据平台 (spolicy.com)
现象:打开调试界面后,进入debug,尝试设置不再此段点停止,但没用。并且debug下再刷新页面,会卡死
分析:
- 卡死:条件满足时(进入
debug时),网站的js代码中有循环在不断的往内存中写数据,造成卡死
解决办法:
添加
hook,修改debug触发的条件绕过。Source面板新建脚本
1
2
3
4
5
6
7
8var ins = Function.prototype.constructor;
Function.prototype.constructor = function (params) {
if(params != "debugger") {
return ins(params);
}
return function() {};
}ctrl+enter执行钩子后,点击继续执行脚本,就不会卡死了
优化:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20// 保存原始的 Function 构造函数
const originalFunctionConstructor = Function.prototype.constructor;
// 修改 Function 构造函数的行为
Function.prototype.constructor = function (...args) {
if (args.length > 0 && args[0] !== "debugger") {
return new originalFunctionConstructor(...args);
}
return function() {};
};
// 测试
const normalFunction = new Function('console.log("Normal function");');
const debugFunction = new Function('debugger;', 'console.log("Debug function");');
const customFunction = new Function('custom code here');
normalFunction(); // 输出: "Normal function"
debugFunction(); // 不会触发 debugger,输出: "Debug function"
customFunction(); // 不会触发 debugger
即使可以调试了,但也可能会报错,可以尝试本地js替换
本地js替换
有些地方打断点后,会出现报错(该位置打不上断点)
可以尝试下本地js替换
反debugger的几种方式
网页端debugger反调试的几种对抗方式 - 狼人:-) - 博客园 (cnblogs.com)
禁用F12和右键
这样的反调试可以通过 Ctrl + Shift + i 打开控制台
其他:
Microsoft Edge浏览器内置Web开发工具——DevTools打开与关闭方式说明 - Edge浏览器
将 DevTools 放置 (Undock、Dock 更改为底部、停靠到左侧) - Microsoft Edge Development | Microsoft Learn
停用断点

点击切换成这个样子后,已经停用了断点调试,无限debugger将消失。然后再启动脚本即可
如果只是从干掉debugger的层面上讲,那么我们的目的已经达到了。但是这种方法不好用,干掉debugger的同时,也无法再对该网页进行任何调试。然而往往我们打开F12就是为了调试,你把调试给禁了,我开F12干嘛。。
添加条件断点
想必各位对如下打断点的方式并不陌生:
点击代码行数就会添加断点。这是普通断点的快捷添加方法。在浏览器中还有一种条件断点。
条件断点与打常规断点的方法类似,在要添加的行号上右键,选择Add conditional breakpoint:
然后输入false,回车:
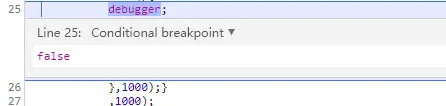
代码变成了这个样子:
然后点击继续执行
Never Pause Here
使用Fiddler替换文件
先右键点击查看网页源代码,把源代码拷贝下来一份,放到我们写好的html中,
然后修改代码,把debugger置为false,
Fiddler中找到要替换的请求:把他拖进AutoResponser中:
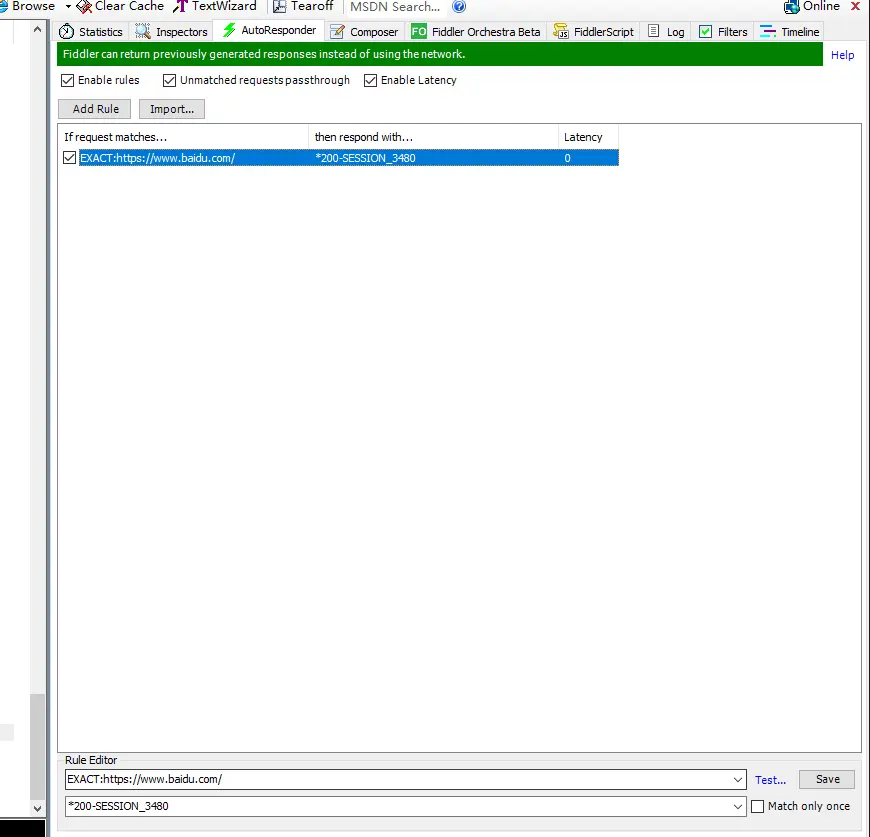
刷新页面。
脚本注入
方法四是比较方便的,但是有时候你会发现要修改的JS代码是动态的,每次加载都不一样,这时候如果盲目替换文件,很可能导致网页的逻辑无法使用。我们仅仅需要把debugger的地方干掉就可以了。
也就是,通过注入,修改指定代码。细心的你可能已经发现了,这不就是上面我们注入debugger做的事吗?是的。。。所以,没有看上面方法四的建议回去看一下。。。方法类似,指定Host,用正则替换掉debugger代码。
这里不再讲了。
JS HOOK劫持
首先要装一个油猴插件,这个程序员应该都装了吧。。。实现各种骚操作。
js的hook和Frida中的很像,或者说比Frida的hook更简单。我们现在知道了debugger是在setInterval中执行的,那我们尝试劫持setInterval。点击这里,新建一个油猴脚本:
1 | // ==UserScript== |
run-at document-start表示在加载的时候运行
其实通过这些,学到的不仅仅是针对反调试,这些方法在其他的地方也有相当多的应用场景。比如Hook,这么好用的方法难道仅仅用来对付反调试?不不不,他还可以hook任意JS加密方法,hook Cookie的生成,hook一个搜索不到的入口等等等。。留给大家自己研究了。
如果后续我找到新的对付无限debugger的方法,也会更新在这里。
案例
http://www.aqistudy.cn/
【JS逆向系列】某空气质量监测平台无限 debugger 与 python算法还原_检测到非法调试,请关闭调试终端_渔滒的博客-CSDN博客
Python 爬虫进阶必备 | 以 aqistudy 为例的无限 debugger 反调试绕过演示(附视频) - 知乎 (zhihu.com)
禁用了F12和右键,这样的反调试可以通过 Ctrl + Shift + i 打开控制台
打开控制台之后看到提示debugger

这样的 debugger ,可以在堆栈里翻看上一层堆栈看看能否置空函数来防止进入 debugger

通过堆栈可以看到txsdefwsw这个方法调用了debugger

这个方法是在首页调用的,试了下txsdefwsw = function(){}
发现还是会出现调用,再看堆栈,发现原来还有setInterval循环调用了检测逻辑


可以看到上图的堆栈,最顶层是city_realtime.php
在这个堆栈里找到了两个eval

所以这个网站的整套逻辑我猜是下面这样的
1 | 1、请求目标网站 |
知道这个套路之后我们要这么反反调试?
1、本地代理这个首页,替换首页的eval
这个法子的工具用 Fiddler 或者 Reres ,用规则匹配到这个页面然后替换就好了,网上的资料很多或参考之前的文章
2、使用如下视频的方法调试,可以在 vm 的生命周期内不用理会 debugger
有读者试过视频中的方法,但是就是不行,这是为啥?
这里可能是忽略了一个小细节,这个可以在代码中找到答案

这里检测了 window 的内外长宽,当我们打开控制台,原有展示的页面就小了,所以只要把控制台调整成一个新的窗口就可以规避,接着使用视频展示的就可以了。
除此之外,还有读者好奇eval里面的dxYKI84fjg还有d1JR0RXxxgp逻辑在哪,进不到具体逻辑里

可以像我这样在控制台输入函数名,然后点击回显的内容就可以自动跳到对应的逻辑了,这个方法适用于没有重写过toString方法的函数。
关于 debugger 反调试的形式很多,但是检测的方法大同小异,重要的是理解他为什么会出现 debugger ,先知道原理才知道如何绕过。
以上,就是今天的全部内容了,我们下次再会~
app逆向
查壳
脱壳
反编译
验证码
基础
反爬机制:验证码,识别验证码图片中的数据,用于模拟登录操作。
识别验证码的操作:
- 人工肉眼识别(不操作)
- 第三方自动识别
云打码使用流程
云打码平台
http://www.ttshitu.com/docs/index.html?spm=null
Tesseract-OCR完成验证码训练
(时间成本、学习成本过高,略过)
古诗文网验证码识别
1 | def base64_api(uname, pwd, img, typeid): with open(img, 'rb') as f: base64_data = base64.b64encode(f.read()) b64 = base64_data.decode() data = {"username": uname, "password": pwd, "typeid": typeid, "image": b64} result = json.loads(requests.post("http://api.ttshitu.com/predict", json=data).text) if result['success']: return result["data"]["result"] else: return result["message"] return ""def parse_ocr(img_path,uname,pwd): result = base64_api(uname, pwd, img=img_path, typeid=3) print(result) def query_account_nfo(username, password): url = 'http://api.ttshitu.com/queryAccountInfo.json?username='+username+'&password='+password result = requests.get(url=url,headers=HEADERS).text print(result) |
验证码技术
- 腾讯防水墙,异常用户检测风控(外包市场,一个技术点7000左右)
- 阿里无感 v3
- 极验4代 点选(图像、文字)(4000)
- 小红书 数美验证
- 百度 旋转验证
- 网易 易盾验证
- 顶象
上述就不要说用什么云打码了
个人的不要怕,不要怕被发律师函啥的,一般只会对规模化的大公司
详细内容搜索验证码逆向
数美验证
智能验证码体验_图片验证码_数美科技 (ishumei.com)
基本逻辑:
- 网站先加载验证码图片资源,等待用户操作验证
- 验证失败,重新获取验证码图片(包括前景图片和后景图片)
注意点
获取验证码的接口,和校验的接口参数,是同频的(有关联的),两者要能对的上
刷新页面重新请求或者多开一个窗口,看同一个接口的前后参数是不是动态变化的
fverify验证接口每次请求的字段位置它给调整了,发现有的字段是变化的,有的是固定的哪些是没有变化的,记录下来
可以多验证几次,这里可以自己写个工具,或者找个工具网站,去识别两次或多次
headers参数中变化的key或者value,这样就不用一个一个对字段了。最后多次测试发现,那种值形如
zY8brT9SISY=的,都是固定的,详细如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24params = {
'ra': 'hxr/MjNHA9Q=', # 变化
'ml': 'jIMH9Nqk+AENn//Xs7iHWff3lKevt297', # 变化
'ee': 'b6/OUymOq6je7Wbu0+VkXfdYSQU4SgBGVtzNwGItgbVHMpXnjP7oxlVMQDEzstcy2iD9dgq5FVxu23c8mvH7fzCF0d5UsCzjnSjOC85sZjg2JeY6M8eTD/4JuVBcnHTdQHkabMvaQyZylKnZpCsd3A==', # 变化,轨迹
'callback': 'sm_1693773372016', # 变化
'organization': 'd6tpAY1oV0Kv5jRSgxQr', # 同频字段
'sdkver': '1.1.3', # 同频字段
'rversion': '1.0.4', # 同频字段
'rid': '2023090404364815c0f648a85b41af37', # 由加载验证码的接口返回
'captchaUuid': '202309040434008Ji5eJxzjeMzTR4peX', # 验证码id,刷新页面会变化,同一个会话不会变化
'ostype': 'web', # 无变化
'us': 'zY8brT9SISY=', # 无变化
'hd': 'w6ArMUdGI6s=', # 无变化
'xy': 'xIAv2QAUoJA=', # 无变化
'jn': 'w6ook9DZFNo=', # 无变化
'ma': 'Ku1yrQmmWo8=', # 无变化
'protocol': '179', # 无变化
'act.os': 'web_pc', # 无变化
'xc': 'MPQBHp3MK74=', # 无变化
'jv': 'tnws0FUkt6c=', # 无变化
'qu': 'Q/IW6xhk8TI=', # 无变化
'rj': 'LpMN9yrHH3I=', # 无变化
}
gif验证码
人机交互
美团 人机交互
变现思路
工商数据(如企查查)
运营数据
- 直播运营数据
- 评论数据
垂直领域
- 裁判文书网:很多律师团队都要想要
监控爬虫
- 抢票
- 抢购
海外项目接单
做成软件或者
web应用,按账号出售
 wechat
wechat alipay
alipay
