
Excel治理与入库
引言
场景
虽然数据库技术和大数据已经广泛使用,公司打造内部数据平台时,对基于关系型数据库,或者是格式标准的文件,例如JSON,XML,CSV等数据一体化都相对容易。因为这些数据载体标准,变化可控,易于分辨,且都有成熟的工具/包,来辅助抽取和解析。
生产生活中,Excel文件仍然是常见数据承载媒介。公司运作的过程中,也会产生很多有价值的数据,存在易于阅读和方便传播的Excel文件中。Excel文件没有统一的格式,数据编排方式完全依赖个人的习惯和偏好,不可能被标准化。
当想把这些数据落地存储为公司的数据资产时,很难用一套通用程序来处理。虽然现在满天飞各种数据中台类产品,但只能解决企业内标准化数据源(90%都是关系型数据库)的整合问题,几乎不涉及存储在excel中的数据,导致这些文件中的数据都是游离在公司数据体系之外的。
适用对象
哪些情景,或者说工作环境中有对Excel数据治理的需求呢?总结了一下大概分成四类:
工作业务流程接触很多excel中的时序数据。这些文件可能是内部产生的,也可能是外部产生的。主要依靠人阅读的方式消费文件,需要提升效率;
公司产生很多有价值的数据,都在excel中,想把它数字资产化;
公司有一定的IT基础,数据架构很完善,数据中台基本都已成型,想打通零散的Excel线下数据;
数据公司。汇聚各类细分数据源的Excel文件,生产自己的EDB指标;
痛点
要完成上面的目标,有个痛点一定绕不过去,就是自由格式的Excel文件解析。 Excel传统上一般有3种处理方式:
1. 格式简单/标准
标准的二维矩阵形式,可用ETL工具直接导入。比如kettle,指定sheet名,数据起始的行列,preview一下数据,自动识别出列的格式,生成二维表。
直接用Python中的pandas读取也都很容易;或者Navicat都可以把直接导入数据库表中。
2. 格式复杂
有两种处理方式:
2.1 定义一个中间标准模板态(一个模板Excel)。把非标准形式的excel文件手工往这个形式转换,后者再用程序批量处理;
2.2 对每个Excel文件的每个sheet,写单独的程序去解析;
即使通过上面几种方式实现了,当文件中的数据内容、排版方式发生变化时,比如数据中间插入了一行或者一列,某个sheet改名了,单元格的指标名称改了等等,靠人或者程序去识别这类变化,都非常困难;文件改变后,还要对(手工)转换过程或者代码做相应的修改和测试,也很耗时。
识别文件内容变化,以及根据变化迅速调整处理逻辑,是解析的难点。当然,更为重要的,是用低成本(人、时间)迅速响应数据格式的变化。
格式自由
Excel格式因人而异,没有标准,想怎么弄就怎么弄。比如:
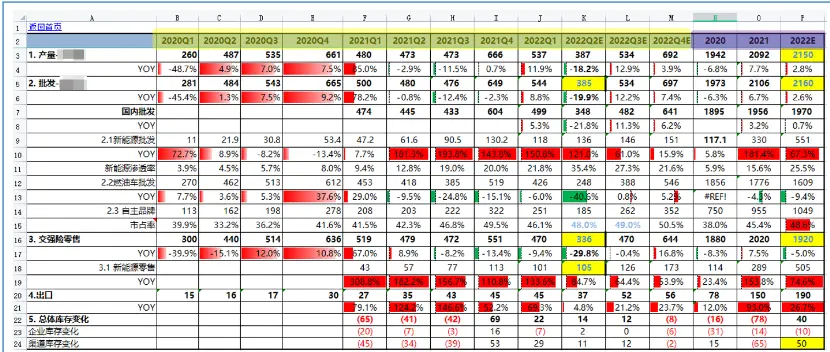
季频和年频数据混合,且都有预测值。A列的含义丰富,既有分类,又有不同指标,还有同比
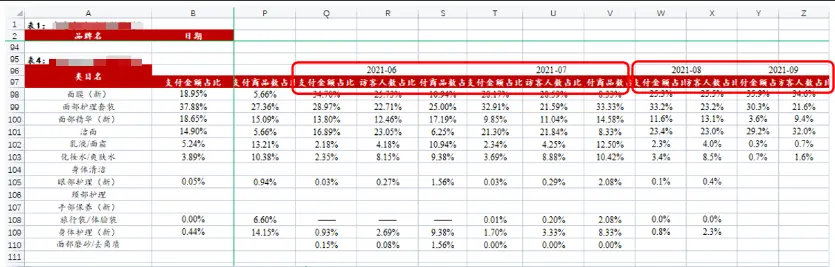
6月和7月每个日期下面有3个指标;8月之后,每个日期就只有2个指标了;日期是合并单元格;

水平+垂直方向组合才构成完整的日期;A列看到的值和真实的值不同;

A,B,C三列组合为日期;日期是合并单元格;旬频定位不到具体的日期值;

两行组合为日期;上中旬、月(而不是下旬)混合;A列的值有层级关系;
上面只是个别样例,真实的情况难以穷尽,各种让人“大开眼界”的格式都会出现。
治理目标
Excel解析在很多公司和人的眼中,只是个小东西,随便找个人,写写Python就能搞定的,这没错,但为何笔者认为需要一个专业的Excel治理方案呢?

主流方法把Excel单元格的值抠出来放进表中并不难,但缺点也很明显
kettle等ETL工具,能够处理格式标准的excel文件;最不济,找人针对一个个具体的excel样式写代码,也最终可以把数据导入到数据库中去。可行性是有的,但是解决成本很贵。
Excel治理上,笔者认为有3种段位:
1.数值入库
将单元格读入数据库表中,类似Wind导出的EDB指标,也能保存表头上的单位、数据来源等其他信息;
绝大部分的Excel入库,也只是做到这一步。
2.指标体系
能够增补业务信息、丰富备注、自定义量纲等;建立表中的数值与Excel源文件的对应关系;
3.主题域
分行业、分类型的多维数据集;根据不同业务需求能灵活生成多种表结构;在解析中涵盖数据规划、业务分析的逻辑,沉淀知识;
Excel治理后,应当能够在数据库中重塑原本数值,并将源文件中混乱的值列、维度列存在表单独的列中。
(补充:这部分类似于数仓ods层等分层结构)

将源文件中分散的数据,汇聚到宽表的不同值列和维度列上

将多个Sheet中的数据,在宽表中用不同维度标识出来

将分散在多个数据文件中,具有相似属性的数据合并在一起;
这种标准格式,很容易就能被类似FineBI、Tableau等分析工具读取和进行多维分析。如果是算法挖掘,更加需要诸如地域、颜色、量纲、型号、品牌、渠道等不同维度的标签能清楚地被界定出来,算法才能进行准确和深入的学习。
在整个治理过程中,通过简单的步骤,不但完成分布杂乱数据的ETL过程,还可从业务视角实现数据的融合。能够对不同Sheet,甚至不同文件中具有相同属性、维度的数据进行灵活的聚合和再分配。将不同文件中、不同sheet中的数据进行自定义分类,建立满足企业级使用的表。
最终,还有一个总览的视图,能够统一地看到所有源文件,与不同数据库中的不同表、列之间的映射关系;数据的更新状态、统计检查结果(异常值,疑似重复,缺失等)。能第一时间定位到数据异常是源头问题,还是过程问题。
总结
Excel数据治理,不是简单的单元格数值入库就结束了,而是加强沉淀数据资产,提升数据价值,扩大使用范围,加速数据传播的优势,

最终从三个视角全面提升企业的数据治理水平。
 wechat
wechat alipay
alipay
