
kafka
引言:
第一章:介绍了Kafaka的基本定义、传统消息队列及Kafka的应用场景
第一章、Kafka概述
1.1.定义
Kafka是一个分布式的,基于发布/订阅模式的消息队列(Message Queue / MQ),主要应用于大数据实时处理领域。
- 分布式
- 发布/订阅模式
- 消息队列
1.2.消息队列
1.2.1.传统消息队列的应用领域
MQ传统应用场景之异步处理
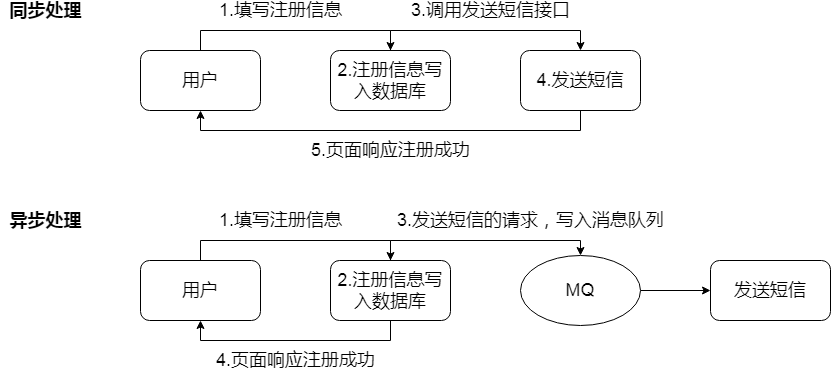
由此图推测MQ应该具备的功能或好处:
- 消息调度
- 提高页面响应时间
1.2.2.使用消息队列的好处
解耦
- 允许你独立的扩展或修改两边的处理过程,只要确保他们遵守同样的接口约束。
可恢复性
- 系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合性,所以即使处理消息的进程挂掉,加入队列的消息仍可以在系统恢复后被处理。
缓冲
- 有助于优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。
灵活性 & 峰值处理能力
- 在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见,如果为以处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费,使用消息队列,能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷请求而完全崩溃。
异步通信
- 很多时候,用户不想也不需要立即处理消息,消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
1.2.3.消息队列的两种模式
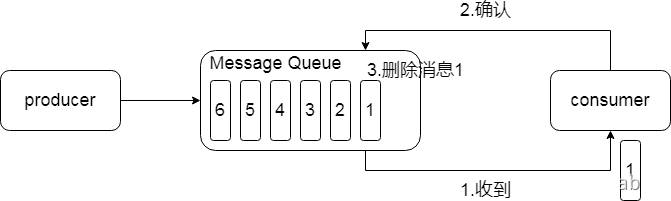
1.2.3.1.点对点模式
一对一,消费者主动拉取数据,消息收到后消息清除
消息生产者生产消息发送到Queue中,然后消息消费者从Queue中取出并且消费消息。消息被消费以后,Queue中不再存储,所以消息消费中不可能消费已经被消费的消息。Queue支持存在多个消费者,但是对一个消息而言,只会有一个消费者可以消费。
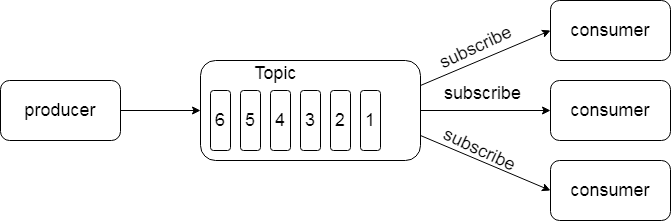
1.2.3.2.发布/订阅模式
一对多,消费者消除数据后不会消除消息
消息生产者(发布)将消息发布到topic中,同时有多个消息消费者(订阅)消费该消息。和点对点方式不同,发布到topic的消息会被所有订阅者消费。
1.3Kafka架构
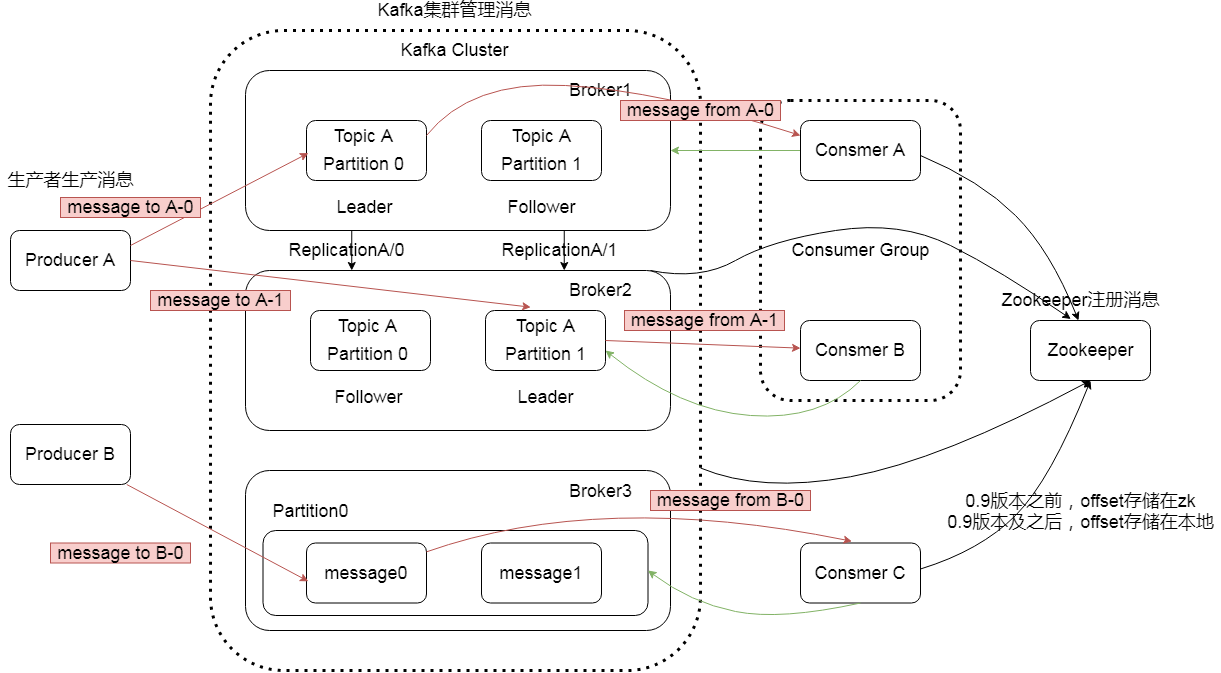
Producer:消息生产者,就是向kafka broker发消息的客户端
Kafka集群:
Broker
- 一台Kafka服务器就是一个Broker,一个集群由多个Broker组成,一个Broker可以容纳多个Topic
- 分布式(Broker1、Broker2、Broker3),每个Broker相当于一个服务器,只不过是启的是Kafka的进程
- 由这三个Broker组成了Kafka集群
- 数据存储在Broker里面
- 数据直接存储在Broker里面吗?
- 不是,消息需要进行分类,由此有了Topic组件
- 发消息和消费消息,直接连接Topic就可以了
Topic
- 可以理解为一个队列,生产者和消费者面向的都是一个topic
Partition
- 为了实现扩展性,一个非常大的Topic可以分布到多个Broker(服务器)上,一个Topic可以分为多个Partition,每个Partition都是一个有序的队列
- Topic中分区(Partition)的作用?
- 提高某一个Topic的负载均衡
- 如上图,一个Topic的两个分区,划在了两台机器上面
- 假设消息以轮询的方式来了,你一条我一条,并不是传给同一台机器的,
- 生产者不再是跟一个机器去连,而是两个机器去连,提升了并发度
Replica
- 副本,为保证集群中的某个节点发生故障时,一个Topic的每个分区都有若干副本,一个Leader和若干Follower
Leader
- 每个分区多个副本的“王”,生产者发送数据的对象,以及消费者消费数据的对象都是Leader
- Leader是针对分区的
- Follower相当于副本,做一个数据的冗余
- Leader和Follower一定不在同一台机器上
- 生产者和消费者,都是找Leader,Follower仅仅起到备份作用,只有Leader挂掉了,才会找Follower
Follower
- 每个分区多个副本中的“从”,实时从Leader中同步数据,保持和Leader数据的同步,Leader发生故障时,某个Follower会成为新的Leader
小结:
- 集群存储的核心是主题(Topic),主题是分区(Partition)的,每个分区是有副本的,并且副本分Leader和Follower的
Consumer:消息消费者,向kafka broker取消息的客户端
- Consumer Group(CG):
- 消费者组,由多个consumer组成,消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内的消费者消费,消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
- 消费者组里消费者的个数,多于分区数是没有意义的,只会空转
- 消费者者组,提高了消费能力
- Consumer Group(CG):
Zookeeper:
- 帮助Kafka集群存储一些信息,Kafka要正常工作,需要依赖于Zk
- 要想Kafka是共用的,把多套Kafka做成一个集群,只要它们所用的Zk是同一套集群就够了
- 消费者也会(临时)存储消费位置信息,运行时是存储在内存里的,挂掉之后重新消费时,从Zk里面读取
- offset信息在0.9版本之前是存储在Zk中的,0.9版本及之后,是存储在系统维护的Topic中
- 为什么要改?
- 消费者本身要和Kafka集群的Leader进行通信,在获取数据的同时,还要维护和Zk的链接
- 消费者是以拉取的方式获取信息的,拉取的速度是非常快的,拉取的同时又要频繁的和Zk打交道,效率地下
- Zk本身是作为各大框架的润滑剂,之前的设计对于Zk也是不友好的
- 改到哪儿了?
- 本地
- 不是本地磁盘,而是存储到了系统维护的Topic中
- Kafka存消息存在磁盘,默认保留7天(168 hours)
- 帮助Kafka集群存储一些信息,Kafka要正常工作,需要依赖于Zk
第二章、Kafka快速入门
2.1.安装部署
2.1.1.集群规划
2.1.2.jar包下载
第三章、Kafka架构深入
第四章、Kafka API
第五章、Kafka监控
第六章、Flume对接Kafka
第七章、Kafka面试题
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 吕小布の博客!
 wechat
wechat alipay
alipay
相关推荐

评论