
redis基础
1.NoSQL数据库简介
2. Redis概述安装
2.1. 应用场景
2.1.1.配合关系型数据库做高速缓存
- 高频次,热门访问的数据,降低数据库IO
- 分布式架构,做session共享
2.1.2.多样的数据结构存储持久化数据
- 最新N个数据:通过List实现按自然时间排序的数据
- 排行榜,TopN:利用zset(有序集合)
- 时效性的数据,比如手机验证码:Expire过期
- 计数器、秒杀:原子性,自增方法:INCR、DECR
- 去除大量数据中的重复数据:利用Set集合
- 构建队列:利用list集合
- 发布订阅消息系统:pub/sub模式
2.2. Redis安装
2.2.1. 安装版本
redis官网 下载官网最新稳定版本
不考虑windows环境下对redis的支持
2.2.2. 安装步骤
准备工作:下载安装最新版的gcc编译器
安装C语言的编译环境
1 | yum install centos-release-scl scl-utils-build |
测试gcc版本
1 | gcc --version |
如果没有,安装gcc
1 | yum install gcc |
下载redis-6.2.4.tar.gz安装包,放在/opt目录下
解压命令
1 | tar -zxvf redis-6.2.4.tar.gz |
解压完成后进入目录
1 | cd redis-6.2.4 |
在redis-6.2.4目录下执行make编译命令
1 | make |
- 如果没有准备好C语言编译环境,make会报错:Jemalloc/jemalloc.h:没有那个文件
- 解决方案:运行
make distclean,安装好编译环境后,再次执行make编译命令
跳过make test命令,执行make install安装命令
- 执行
make test时遇到You need tcl 8.5 or newer in order to run the Redis test- 解决方案:
yum install tcl
- 解决方案:
2.2.3. 安装目录
默认安装在/usr/local/bin目录下
查看默认安装目录:
redis-benchmark:性能测试工具,可以在自己本子运行,看看自己本子性能如何redis-check-aof:修复有问题的AOF文件,rdb和aof后面讲redis-check-dump:修复有问题的dump.rdb文件redis-sentinel:redis集群使用- **
redis-server**:redis服务器启动命令 - **
redis-cli**:客户端,操作入口
2.2.4. 前台启动(不推荐)
前台启动,命令行窗口不能关闭,否则服务器停止
1 | redis-server |
但是前台启动,可以看到读写过程,
配置文件中,更改了save 30 5,表示30s秒5个key发生变化,就进行持久化存储;
连接上redis后,进行如下操作:
1 | 127.0.0.1:6380> ping |
后台记录如下:
1 | 27593:M 31 Jul 2021 10:36:35.320 * Ready to accept connections27593:M 31 Jul 2021 10:40:24.873 * 5 changes in 30 seconds. Saving...27593:M 31 Jul 2021 10:40:24.874 * Background saving started by pid 2824628246:C 31 Jul 2021 10:40:24.887 * DB saved on disk28246:C 31 Jul 2021 10:40:24.887 * RDB: 6 MB of memory used by copy-on-write27593:M 31 Jul 2021 10:40:24.974 * Background saving terminated with success |
2.2.4.2.启动报错信息
WARNING overcommit memory is set to 0
1
WARNING overcommit_memory is set to 0! Background save may fail under low memory condition. To fix this issue add '`vm.overcommit_memory = 1`' to `/etc/sysctl.conf` and then reboot or run the command '`sysctl vm.overcommit_memory=1`' for this to take effect.
解决方案
1
2.2.5. 后台启动(推荐)
redis目录中,有一个文件redis.conf,把它复制到/etc目录下(或自定义目录下)
1 | cp redis.conf /etc/redis.conf |
修改redis.conf(128行)文件将里面的daemonize no 改成yes,让服务在后台启动(可以在vi中按\搜索)
1 | vi redis.conf |
按/进行搜索daemonize,然后修改
进入/usr/local/bin目录下,指定配置文件启动redis
1 | redis-server /etc/redis.conf |
查询启动的redis进程
1 | ps -ef | grep redis |
这种启动方式,即使关闭了命令行窗口,redis仍然是启动状态
此时可以通过redis-cli命令启动redis客户端来连接redis数据库
1 | redis-cli |
多个端口访问:redis-cli -p 6379,如果输入了错误的端口号,虽然可以进入redis终端,但在ping的时候,会报错:
1 | Error: Protocol error, got "H" as reply type byte |
redis终端中输入ping,返回PONG表示是一个正常的连通状态
redis的关闭
单实例关闭:
redis-cli shutdown(未进入redis终端)也可以进入终端后再关闭:
shutdown,然后输入exit退出可以
ps -ef | grep redis查询进程号1
root 22661 1 0 16:44 ? 00:00:00 redis-server 127.0.0.1:6379root 34556 21819 0 17:15 pts/7 00:00:00 grep --color=auto redis
然后
kill -9 22661杀掉redis进程即可配置密码
- 搜索
requirepass foobared,然后修改foobared,记得删除#号取消注释 - 连同后,输入
auth 密码即可
- 搜索
卸载redis
- 杀掉所有redis相关进程
- 进入到
user/local/bin目录,删除rm -rf redis*
- 进入到
- 杀掉所有redis相关进程
2.2.6. Redis介绍相关知识
端口6379从何而来:
Alessia Merz默认16个数据库,类似数组下标从0开始,初始默认使用0号库
统一密码管理,所有库同样密码
dbsize查看当前数据库的key的数量flushdb清空当前库flushall通杀全部库
Redis是单线程+多路IO复用技术
多路IO复用是指使用一个线程来检查多个文件描述符(Socket)的就绪状态,比如调用select和poll函数,传入多个文件描述符,如果有一个文件描述符就绪,则返回,否则阻塞直至超时。
得到就绪状态后进行真正的操作,可以在同一个线程里执行,也可以启动线程执行(比如使用线程池)
串行 vs 多线程 + 锁(memcached) + 单线程 + 多路IO复用(Redis)
(与Memcache三点不同:支持多数据类型,支持持久化,单线程 + 多路IO复用)
3.常用五大数据类型
3.1.Redis键(key)
keys *:查看当前库所有key(匹配:keys *1(匹配以1结尾的key键))exsits key:判断某个key是否存在type key:查看你的key是什么类型del key:删除指定的key数据unlink key:根据value选择非阻塞删除- 仅将keys从keyspace元数据中删除,真正的删除在后续异步操作
expire key 10:为给定的key设置过期时间为10秒ttl key:查看还有多少秒过期,-1表示永不过期,-2表示已过期
select 1:切换数据库1dbsize:查看当前库的key的数量flushdb:清空当前库flushall:通杀全部库
3.2.Redis字符串(String)
3.2.1.简介
String是Redis最基本的数据类型,一个key对应一个value
String类型是二进制安全的,意味着Redis的string可以包含任何数据。比如jpg图片或者序列化的对象(一个文件,只要能转换成字符串,都可以存到Redis中)
String类型是Redis最基本的数据类型,一个Redis中字符串value最多可以使512M
3.2.2.常用命令
set <key> <value>添加键值对get <key>查询对应键值1
127.0.0.1:6379> set k1 v1 [EX seconds|PX milliseconds|EXAT timestamp|PXAT milliseconds-timestamp|KEEPTTL] [NX|XX] [GET]set k1 v1set k1 v2get k1 # "v2",对同一个key设置,会覆盖原来的
*NX:当数据库中key不存在时,可以将key-value添加数据库
*XX:当数据库key存在时,可以将key-value添加数据库,与NX参数互斥
*EX:key的超时秒数
get <key>:查询对应键值append <key> <value>:将给定的<value>追加到原值的末尾strlen <key> <value>:获得值的长度setnx <key> <value>:只有在key不存在时,设置<key>的值incr <key>- 将
<key>中存储的数字值增1 - 只能对数字值操作,如果为空,新增值为1
- 将
decr <key>- 将key中存储的数字值减1
- 只能对数字值操作,如果为空,新增值减1
incrby/decrby <key> <步长>:将key中存储的数字值增减,自定义步长
原子性:
incr key:对存储在指定key的数值执行原子的加1操作- 起始版本:1.0.0
- 时间复杂度:O(1)
所谓原子操作,是指不会被线程调度机制打断的操作
这种操作一旦开始,就一直运行到结束,中间不会有任何
context switch(切换到另一个线程)- 在单线程中,能够在单条指令中完成的操作都可以认为是“原子操作”,因为中断只能发生于指令质检
- 在多线程中,不能被其它进程(线程)打断的操作就叫原子操作。
Redis单命令的原子性主要得益于Redis的单线程
案例
1
Java中的i++是否是原子操作? 不是,先取值,再++,再赋值i=0,两个线程分别对i进行i++100次,值是多少? 2~200
mset <key1> <value1> <key2> <value2>- 同时设置一个或多个key-value对
mget <key1> <key2> <key3>- 同时获取一个或多个value
msetnx <key1> <value1> <key2> <value3>- 同时设置一个或者多个key-value,当且仅当给定key都不存在
getrange <key> <起始位置> <结束位置>- 获得值的范围,类似java中的substring,前包,后包
setrange <key> <起始位置> <value>- 用
<value>覆写key所存储的字符串值,从<起始位置>开始(索引从0开始)
- 用
setex <key> 过期时间 <value>- 设置键值的同时,设置过期时间,单位:秒
getset <key> <value>- 因新换旧,设置了新值的 同时获得旧值
3.2.3.数据结构
String的数据结构为简单动态字符串(Simple Dynamic String,缩写是SDS)。是可以修改的字符串,内部结构实现上类似于Java的ArrayList,采用预分配冗余空间的方式来减少内存的频繁分配。

如图所示,内部为当前字段串实际分配的空间capacity一般要高于字符串实际长度len。当字符串长度小于1M时,扩容都是加倍现有的空间,如果超过1M,扩容时一次只会多扩1M的空间。需注意的是字符串的最大长度为512M。
3.3.Redis列表(List)
3.3.1.简介
单值多键
Redis列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)。
它的底层实际是个双向链表,对两端的操作性能很高,同构索引下标来操作中间的节点性能会较差。

3.3.2.常用命令
lpush/rpush <key> <value1> <value2> <value3>...- 从左边/右边插入一个或多个值
lpop/rpop <key>- 从左边/右边吐出一个值。值在键在,值光键亡。
rpoplpush <key1> <key2>- 从
<key1>列表右边吐出一个值,插到<key2>列表左边。
- 从
lrange <key> <start> <stop>- 按照索引下标获得元素(从左到右)
lrange mylist 0 -1- 0:左边第一个
- -1:右边第一个
- 表示获取所有
index <key> <index>- 按照索引下标获取元素(从左到右)
llen <key>- 获得列表长度
linsert <key> before/after <value> <newvalue>- 在
<value>的前面/后面插入<newvalue>插入值
- 在
lrem <key> <n> <value>- 从左边删除n个value(从左到右)
lset <key> <index> <value>- 将列表
<key>下标为index的值替换成value
- 将列表
3.3.3.数据结构
List的数据结构为快速链表quicklist。
首先在列表元素较少的情况下会使用一块连续的内存存储,这个结构是ziplist,也即是压缩列表。
它将所有的元素紧挨着一起存储,分配的是一块连续的内存。
当数据量比较多的时候才会改成quicklist。
因为普通的链表需要的附加指针空间太大,会比较浪费空间。比如这个列表里存的只是int类型的数据,结构上还需要两个额外的指针prev和next。

redis将链表和ziplist结合起来组成了quicklist。也就是将多个ziplist使用双向指针串起来使用。这样既满足了快速的插入删除性能,又不会出现太大的空间冗余。
3.4.Redis集合(Set)
3.4.1.简介
Redis set对外提供的功能与list类似是一个列表的功能,特殊之处在于set是可以自动排重的,当你需要存储一个列表数据,又不希望出现重复数据时,set是一个很好的选择,并且set提供了判断某个成员是否在一个set集合内的重要接口,这个也是list所不能提供的。
Redis的Set是String类型的无序集合。它底层其实是一个value为null的hash表,所以添加,删除,查找的复杂度都是O(1)。
一个算法,随着数据的增加,执行时间的长短,如果是O(1),数据增加,查找数据的时间不变。
3.4.2.常用命令
sadd <key> <value1> <value2>...- 将一个或多个member元素加入到集合key中,已经存在的member元素将被忽略
smembers <key>- 取出该集合的所有值
sismember <key> <value>- 判断集合
<key>是否含有该<value>值,有1,没有0
- 判断集合
scard <key>- 返回该集合的元素个数
srem <key> <value1> <value2>…- 删除集合中的某个元素
spop <key>- 随机从该集合中吐出一个值
srandmember <key> <n>- 随机从该集合中取出n个值,不会从集合中删除
smove <source> <destiantion> value- 把集合中的一个值从一个集合移动到另一个集合
sinter <key1> <key2>- 返回两个集合的交集元素
sunion <key1> <key2>- 返回两个集合的并集元素
sdiff <key1> <key2>- 返回两个集合的差集元素(key1中的,不包含key2中的)
3.4.3.数据结构
Set数据结构是dict字典,字典使用哈希表实现的。
Java中的HashSet的内部实现使用的是HashMap,只不过所有的value都指向同一个对象。
Redis的set结构也是一样,它的内部结构也使用hash结构,所有的value都指向同一个内部值。
3.5.Redis哈希(Hash)
3.5.1.简介
Redis hash是一个键值对集合
Redis hash是一个string类型的field和value的映射表,hash特别适合用于存储对象。
类似Java里面的Map<StringObject>
用户ID为查找的key,存储的value用户对象包含姓名,年龄,生日等信息,如果用普通的key/value结构来存储
主要有以下2中存储方式:
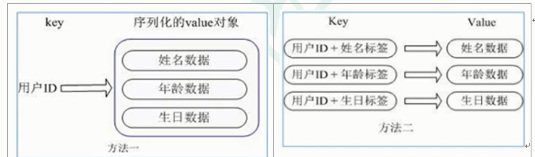
方法一:每次修改用户的某个属性,需要先反序列化,改好后再序列化回去,开销较大
方法二:用户ID数据冗余
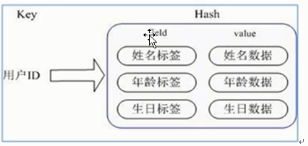
方法三:通过key(用户ID)+field(属性标签)就可以操作对应属性数据了,既不需要重复存储数据,也不会带来序列化和并发修改控制的问题
3.5.2.常用命令
hset <key> <field> <value>- 给
<key>集合中的<field>键赋值<value>
- 给
hget <key> <field>- 从
<key>集合<field>取出<value>
- 从
hmset <key> <field1> <value1> <field2> <value2> ...- 批量设置hash的值
hexists <key> <field>- 查看哈希表key中,给定域field是否存在
hkeys <key>- 列出该hash集合的所有field
hvals <key>- 列出该hash集合的所有value
hincrby <key> <field> <increment>- 为哈希表key中的域filed的值加上增量1(-1)
hset <key> <field> <value>- 将哈希表key中的域field的值设置为value,当且仅当域field不存在
3.5.3.数据结构
Hash类型对应的数据结构是两种,ziplist(压缩列表),hashtable(哈希表),当field-value长度较短且个数较少时,使用ziplist,否则使用hashtable
3.6.Redis有序集合Zset(set)
SortedSet(zset)是Redis提供的一个非常特别的数据结构,一方面它等价于Java的数据机构Map<String,Double>,可以给每一个元素value赋予一个权重score,另一方面它又类似于TreeSet,内部的元素会按照权重score进行排序,可以得到每个元素的名次,还可以通过score的范围来获取元素的列表
3.6.1.简介
Redis有序集合zset和普通集合非常相似,是一个没有重复元素的字符串集合。
不同之处是每个有序集合的每个成员都关联了一个评分(score),这个评分(score)被用来按照从最低分到最高分的方式排序集合中的成员。集合的成员是唯一的,但是评分可以是重复的。
因为元素是有序,所以你也可以根据评分(score)或者次序(position)来获取一个范围内的元素。
访问有序集合的中间元素也是非常快的,因此你可以使用有序集合作为一个没有重复成员的智能列表。
3.6.2.常用命令
zadd <key1> <score1> <key2> <score2>- 将一个或多个member元素及其score值加入到有序集key当中
zrange <key> <start> <stop> [WITHSCORES]- 返回有序集key中,下标在
<start> <stop>之间的元素 - 带
WITHSCORES可以让分数一起和值返回到结果集
- 返回有序集key中,下标在
3.6.3.数据结构
3.6.4.跳跃表(跳表)
4.Redis配置文件介绍
5.Redis的发布和订阅
5.1.什么是发布和订阅
Redis发布/订阅(pub/sub)是一种消息通信模式:发送者(pub)发送消息,订阅者(sub)接收消息。
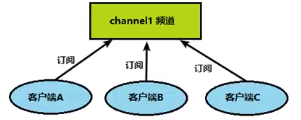
Redis客户端可以订阅任意数量的频道。
5.2.Redis的发布和订阅
1.客户端可以订阅频道
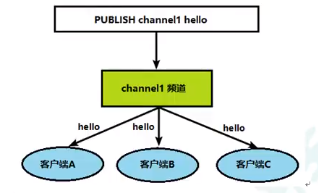
2.当给这个频道发布消息后,消息就会发送给订阅的客户端
5.3.发布订阅命令行实现
1.打开一个客户端订阅channel1
subscribe channel1
2.打开另外一个客户端,给channel1发布消息hello
publish channel1 hello
返回的1是订阅者的数量
3.打开第一个客户端可以看到发送的消息
注:发布的消息没有持久化,如果在订阅的客户端接受不到hello,只能收到订阅后发布的消息。
6.Redis6-新数据类型
6.1.Bitmaps
6.1.1.简介
现代计算机用二进制(位)作为信息的基础单位,1个字节等于8位,例如”abc”字符串是由3个字节组成,但实际在计算机存储时将其用二进制表示,”abc”分别对应的ASCII码分别是97、98、99,对应的二进制分别是01100001、01100010、01100011,如下图:
image
合理地使用操作位能够有效地提高内存使用率和开发效率。
Redis提供了Bitmaps这个“数据类型”,可以实现对应的位操作。
(1)Bitmaps本身不是一种数据类型,实际上它就是一个字符串(key-value),但是它可以对字符串进行位操作。
(2)Redis单独提供了一套命令,所以在Redis中使用Bitmaps和使用字符串的方法不太相同。可以把Bitmaps想象成一个以位为单位的数组,数据的每个单元只能存储0和1,数据的下标在Bitmaps中叫做偏移量。
image
6.1.2.命令
1.setbit
(1)格式
setbit <key> <offset> <value>- 设置Bitmaps中某个偏移量的值(0或1)
- offset:从0开始
(2)实例
每个独立用户是否访问过网站,存放在Bitmaps中,将访问的用户记录记做1,没有访问的用户记做0,用偏移量作为用户的id。
设置键的第offset个位的值(从0算起),假设现在有20个用户,userid=1,6,11,15,19的用户对网站进行了访问,那么当前Bitmaps初始化结果如图
image
1
unique:users:20201106代表2020-11-06这天独立访问用户的bitmaps
注:很多应用的用户id以指定一个数字(例如10000)开头,直接将用户id和Bitmaps的偏移量对应势必会造成一定的浪费,通常的做法是每次做setbit操作时将用户id减去这个指定数字。
在第一次初始化Bitmaps时,假如偏移量非常大,那么整个初始化过程执行会非常缓慢,可能会造成Redis的阻塞。
2.getbit
(1)格式
getbit <key> <offset>- 获得Bitmaps中某个偏移量的值
- 获取键的第offset的值(从0开始计算)
(2)实例
获取id=8的用户是否在2020-11-06这天访问过,返回0说明没有访问过:
getbit unique:users:20201106 19
3.bitcount
统计字符串被设置为1的数。一般情况下,给定的整个字符串都会被进行计数,通过指定额外的start或end参数,可以让计数只在特定的位上进行。start和end参数的设置,都可以使用负数值:比如-1表示最后一个位,而-2表示倒数第二个位,start、end是指bit组的字节的下表述,二者皆包含。
(1)格式
bitcount <key> [start end]- 统计字符串从start字节到end字节比特值为1的数量
(2)实例
计算2022-11-06这天的独立访问用户数量
bitcount unique:users:20201106
start和end代表起始和结束字节数,下面操作计算用户id在第1个字节到第3个自己之间的独立访问用户数,对应的用户id是11,15,19。
bitcount unique:users:20201106 1 3
注意:redis的setbit设置或清除的是bit位置,而bitcount计算的是byte位置。
4.bitop
(1)格式
bitop and(or/not/xor) <destkey> [key...]- bitop是一个复合操作,它可以做多个Bitmaps的and(交集)、or(并集)、not(非)、xor(异或)操作并将结果保存在destkey中。
(2)实例
2020-11-04日访问网站的userid=1,2,5,9
setbit unique:users:20201104 1 1
setbit unique:users:20201104 2 1
setbit unqiue:users:20201104 5 1
setbit unique:users:20201104 9 1
2020-11-03日访问网站的useid=0,1,4,9
setbit unique:users:20201103 0 1
setbit unique:users:20201103 1 1
setbit unique:users:20201103 4 1
setbit unique:users:20201103 9 1
计算出两天都访问过网站的用户数量
bitop and unique:users:and:20201104_03 unique:users:20201103 unique :users:20201104
image
计算出任意一天都访问过网站的用户数量(例如月活跃就是类似这种),可以使用or求并集
bitcount unique:users:or:20201104_03
6.1.3.Bitmaps和set对比
假设网站有1亿用户,每天独立访问的用户有5千万,如果每天用集合类型和Bitmaps分别存储活跃用户就可以得到表
set和Bitmaps存储一天活跃用户对比
| 数据类型 | 每个用户id占用空间 | 需要存储的用户量 | 全部内存量 |
|---|---|---|---|
| set | 64位 | 50000000 | 64位*5000000=400MB |
| Bitmaps | 1位 | 100000000 | 1位*100000000=12.5MB |
很明显,这种情况下使用Bitmaps能节省很多的内存空间,尤其是随着时间推移,节省的内存还是非常可观的。
set和Bitmaps存储独立用户空间对比
| 数据类型 | 一天 | 一个月 | 一年 |
|---|---|---|---|
| set | 400MB | 12GB | 144GB |
| Bitmaps | 12.5MB | 375MB | 4.5GB |
但Bitmaps并不是万金油,加入该网站每天的独立访问用户很少,例如只有10万(大量的僵尸用户),那么两者的对比如下表所示,很显然,这时候使用Bitmaps就不太合适了,因为基本上大部分位都是0。
set和Bitmaps存储一天活跃用户对比(独立用户比较少)
| 数据类型 | 每个userid占用空间 | 需要存储的用户量 | 全部内存量 |
|---|---|---|---|
| set | 64位 | 100000 | 64位*100000=800kb |
| Bitmaps | 1位 | 100000000 | 1位*100000000=12.5MB |
6.2.HyperLogLog
6.2.1.简介
在工作当中,我们经常会遇到和统计相关的功能需求,比如统计网站PV(PageView页面访问量),可以使用Redis的incr、incrby轻松实现。
但像UV(UniqueVisitor,独立访客)、独立IP数、搜索记录数等需要去重和计数的问题如何解决?这种求集合中不重复元素个数的问题称为基数问题。
解决基数问题的方法有很多种方案:
(1)数据存储在MySQL中,使用distinct count计算不重复个数
(2)使用Redis提供的hash、set、bitmaps等结构来处理
以上的方案结果精确,但随着数据不断增加,导致占用空间越来越大,对于非常大的数据集是非常不切实际的。
能否能够降低一定的精度来平衡存储空间?Redis推出了HyperLogLog。
Redis HyeprLogLog是用来做基数统计的算法,HyperLogLog的优点是,在输入元素数量或者体积非常大时,计算基数所需的空间总是固定的,并且是很小的。
在Redis里面,每个HyperLogLog键只需要花费12KB内存,就可以计算接近2^64个不同元素的基数。这和计算基数时,元素越多耗费内存越多的集合形成鲜明对比。
但是,因为HyperLogLog只会根据输入元素来计算基数,而不会储存元素本身,所以HyperLogLog不能像集合那样,返回输入的各个元素。
什么是基数?
比如数据集{1,3,5,7,5,7,8},那个这个数据集的基数集为{1,3,5,7,8},基数(不重复的元素)为5。基数估计就是在误差可接受的范围内,快速计算基数。
6.2.2.命令
1.pfadd
(1)格式
pfadd <key> <element> [element...]- 添加指定元素到HyperLogLog中
(2)实例
pfadd program "java" "python"
将所有元素添加到指定HyperLogLog数据结构中。如果执行命令后HLL估计的近似基数发生变化,则返回1,否则返回0.
2.pfcount
(1)格式
pfcount <key> [key...]- 计算HLL的近似基数,可以计算多个HLL,比如用HLL存储每天的UV,计算一周的UV可以用7天的UV合并计算即可。
(2)实例
pfcount program
3.pfmerge
(1)格式
pfmerge <destkey> <sourcekey> [sourcekey...]- 将一个或多个HLL合并后的结果存储在另一个HLL中,比如每月活跃用户可以使用每天的活跃用户来合并计算可得。
(2)实例
6.3.Geospatial
6.3.1.简介
Redis3.2中增加了对GEO类型的至此。GEO,Geographic,地理信息的缩写。该类型,就是元素的2维坐标,在地图上就是经纬度。
Redis基于该类型,提供了经纬度设置,查询,范围查询,经纬度Hash等常见操作。
6.3.2.命令
1.geoadd
(1)格式
geoadd <key> <longtiude> <latitude> <member> [longtitude latitude member...]- 添加地理位置(经度、纬度、名称)
(2)实例
geoadd china:city 121.47 31.23 shanghai
geoadd china:city 106.50 29.53 chognqing 114.05 22.52 shenzhen 116.38 39.90 beijing
南北极无法直接添加,一般会下载城市数据,直接通过java程序一次性导入。
有效的经度从-180度到180度。有效的纬度从-85.05112878度到85.05112878度
当坐标位置超出指定范围时,该命令会返回一个错误。
已经添加的数据,是无法再往里面添加的。
2.geopos
(1)格式
geopos <key> <member> [member...]- 获得指定地区的坐标值
(2)案例
geopos china:city shanghai
3.geodist
(1)格式
geodist <key> <member1> <member2> [m|km|ft|mi]- 获取两个位置之间的直线距离
(2)实例
获取两个位置之间的直线距离
geodist china:city beijing shanghai km
单位:
m表示单位为米[默认值]
km表示单位为千米
mi表示单位为英里
ft表示单位为英尺
如果用户没有显示地指定单位参数,那么GEODIST默认使用米为单位
4.georadius
(1)格式
georadius <key> <longtitude> radius m|km|ft|mi- 以给定的经纬度为中心,找出某一半径内的元素
(2)实例
georadius china:city 110 30 1000 km
7.python操作Redis
7.1.远程连接redis注意事项:
- bind注释掉或者修改为
0.0.0.0 - 关闭保护模式
protected-mode no - 关闭linux防火墙
- 查看防火墙状态:
systemctl status firewalld - 临时关闭防火墙:
systemctl stop firewalld
- 查看防火墙状态:
- 如果使用的是腾讯云或者华为云等云服务器,请在控制台开启6379端口号。
pip install redis安装redis库- 注意,链接redis的文件名,不能取名为redis
7.1.1.一般连接
1 | from redis import Redis''' 一般连接,使用Redis连接'''conn = Redis(host ='localhost',port = '6379',password = 'foobared',db = 0,decode_responses = True)# host可以是ip地址# decode_responses = True,表示以字符串的格式,存储数据,否则将以二进制存储数据conn.set('k1','v1')value = conn.get('k1')print(value) |
1 | from redis import Redis''' 一般连接,使用StrictRedis连接'''conn = StrictRedis(host='localhost',port='6379',password='foobared',db=0,decode_responsed=True)conn.set('k1','v1')value = conn.get('k1')print(value) |
redis-py提供了两个类Redis和StrictRedis用于实现Redis的命令,StrictRedis用于实现大部分官方的命令,并使用官方的语法和命令,Redis是StrcitRedis子类,用于向后兼容旧版本的redis-py
7.1.2.使用连接池
1 | from redis import Redisfrom redis import ConnectionPool''' 使用连接池,连接Redis库的Redis'''# 创建poolpool = ConnectionPool(host = 'localhost',port = '6379',password = 'foobared',db = 0,decode_responses = True)#传入poolconn = Redis(connection_pool = pool)#下方是获取操作的结果value1 = conn.hget('mark','name')value2 = conn.hmget('mark','name','age','h')value3 = conn.hgeall('mark')# 下方是输出操作结果print(value1,type(value1),sep='类型是:')print(value2,type(value2),sep='类型是:')print(value3,type(value3),sep='类型是:') |
1 | from redis import Redisfrom redis import ConnectionPool''' 使用连接池,连接Redis库的StrictRedis'''pool = ConnectionPool(host='lcoahost',port='6379',password='foobared',db=0,decode_responses=True)conn = StrictRedis(connection_pool = pool)#下方是获取操作的结果value1 = conn.hget('mark','name')value2 = conn.hmget('mark','name','age','h')value3 = conn.hgeall('mark')# 下方是输出操作结果print(value1,type(value1),sep='类型是:')print(value2,type(value2),sep='类型是:')print(value3,type(value3),sep='类型是:') |
redis-py使用connection_pool来管理对一个redis-server的所有连接,避免每次建立、释放连接的开销,默认,每个Redis实例都会维护一个自己的连接池。
可以直接建立一个连接池,然后作为参数Redis,这样就可以实现多个Redis实例共享一个连接池
1 | import rediskwargs = { 'hosts':'127.0.0.1', 'port':'6379', 'decode_responses':'True', 'retry_on_timeout':3, 'max_connections':1024 # 默认2^31} |
7.2.测试相关数据类型
7.2.1.Key
7.2.2.String
7.2.3.List
7.2.4.Set
7.2.5.Hash
7.2.6.Zset
7.3.模拟验证码发送
需求:
1.输入手机号,点击发送后,随机生成6位数字码,2分钟有效
随机验证码
- random
1
# 生成6位数字验证码import randomdef get_code(): code = random.randint(111111,999999) return codecode = get_code()print(code)
2分钟有效
- 把验证码放到redis里面,设置过期时间为120秒
1
# 每个手机每天只能发送3次,验证码放到redis中,设置过期时间
2.输入验证码,点击验证,返回成功或失败
- 判断验证码是否一致
- 从redis中获取验证码,和输入的验证码进行比较
3.每个手机号每天只能输入3次。
- incre每次发送之后+1
- 大于2的时候,提交不能发送
8.Redis_事务、机制、秒杀
8.1.Redis事务的定义
Redis事务是一个单独的隔离操作:事务中所有的命令个都会序列化、按顺序的执行。事务在执行的过程,不会被其他客户端发送来的命令请求打断。
Redis事务的主要作用,就是防止串联多个命令,防止别的命令插队。
8.2.Muti、Exec、discard
从输入命令Muti开始,输入的命令都会一次进入命令序列中,但不会执行,直到输入Exec后,Redis会将之前的命令队列中的命令依次执行。
组队的过程中可以通过discard来放弃组队。
img
成功的情况
1 | 127.0.0.1:6379> multiOK127.0.0.1:6379(TX)> set k1 v1QUEUED127.0.0.1:6379(TX)> set k2 v2QUEUED127.0.0.1:6379(TX)> exec1) OK2) OK |
8.3.事务的错误处理
8.3.1.组队阶段错误
组队阶段中,某个命令出现了报告错误,执行时整个的所有队列都会被取消。
1 | 127.0.0.1:6379> multiOK127.0.0.1:6379(TX)> set k1 v1QUEUED127.0.0.1:6379(TX)> set k2 v2QUEUED127.0.0.1:6379(TX)> set k3(error) ERR wrong number of arguments for 'set' command127.0.0.1:6379(TX)> exec(error) EXECABORT Transaction discarded because of previous errors. |
8.3.2.执行阶段错误
如果执行阶段,某个命令报出了错误,则只有报错的命令不被执行,而其他的命令都会执行,不会回滚。
1 | 127.0.0.1:6379> multiOK127.0.0.1:6379(TX)> set k1 v1QUEUED127.0.0.1:6379(TX)> incr k1QUEUED127.0.0.1:6379(TX)> set k2 v2QUEUED127.0.0.1:6379(TX)> exec1) OK2) (error) ERR value is not an integer or out of range3) OK |
8.4.为什么要做成事务
想象一个场景:有很多人有你的账户,同时去参加双十一抢购。
8.5.事务冲突的问题
8.5.1.例子
- 一个请求想给金额减8000
- 一个请求想给金额减5000
- 一个请求想给金额减1000
img
8.5.2.悲观锁
img
悲观锁(Pessimistic Lock),顾名思义,就是很悲观,每次去拿数据的时候,都认为别人会修改,所以每次在拿数据的时候,都会上锁。这样别人想拿这个数据就会block,直到它拿到锁。
传统的关系型数据库里边就用到了很多这样的锁机制,比如行锁,表锁等,读锁,写锁等,都是在操作之前先加上锁。
8.5.3.乐观锁
img
乐观锁(Opitimistic Lock),顾名思义,就是很乐观,每次去拿数据的时候,都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有更新这个数据,可以使用版本号等机制。
乐观锁适用于多读的应用类型,这样可以提高吞吐量。
Redis就是利用这种check-and-set机制实现事务的。
8.5.4.WATCH key [key…]
在执行multi之前,先执行watch key1 [key2],可以监控一个(或者多个)key,如果在事务之前,这个(或者这些)key被其他命令所改动,那么事务将被打断。
乐观锁在redis中的使用:
终端一:
1 | 127.0.0.1:6379> set balance 100OK127.0.0.1:6379> keys *1) "balance"127.0.0.1:6379> watch balanceOK127.0.0.1:6379> multiOK127.0.0.1:6379(TX)> incrby balance 10QUEUED127.0.0.1:6379(TX)> exec1) (integer) 110 |
终端二:
1 | 127.0.0.1:6379> watch balanceOK127.0.0.1:6379> multiOK127.0.0.1:6379(TX)> incrby balance 20QUEUED127.0.0.1:6379(TX)> exec(nil) |
8.5.5.unwatch
取消WATCH命令对所有key的监视。
如果在执行WATCH命令之后,EXEC命令或DISCARD命令先被执行了的话,那么就不需要再执行UNWATCH了。
8.6.Redis事务三特性
- 单独的隔离操作
- 事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。
- 没有隔离级别的概念
- 队列中的命令没有提交之前都不会实际被执行,因为事务提交前任何指令都不会被实际执行
- 不保证原子性
- 事务中如果有一条命令给执行失败,其后的命令仍然会被执行,没有回滚。
8.7.Reds事务秒杀案例
8.7.1.解决计数器和人员记录的事务操作
img
秒杀逻辑流程图
8.7.2.Redis事务–秒杀并发模拟
使用ab工具模拟测试
- centos6默认安装
- centos7需要手动安装
1.联网:
yum install httpd-tools
2.无网络:
cd /run/media/root/CentOS7 x86_64/Packages(路径和Centos6不同)- 顺序安装
apr-1.4.8-3.el7.x86_64.rpmapr-util-1.5.2-6.el7.x86_64.rpmhttpd-tools-2.4.6-67.el7.centos.x86_64.rpm
输入ab --help来检查是否成功
Usage:ab [options] [http[s]://hostname[:port]/path]
3.测试及结果
通过浏览器测试
ab -n 1000 -c 100 http://127.0.0.1:8080/test- -n 表示请求次数
- -c 表示并发次数
- -t 表示content-type
- -p 表示postfile,post提交时存放参数的位置,需要创建一个文件
再通过ab测试
ab -n 1000 -c 100 -p postfile ~/postfile -T application/x-www.form-urlencoded http://127.0.0.1:8080/test- postfile内容:
prodid=0101& ~表示当前目录
- postfile内容:
4.超卖问题
5.连接超时问题
6.库存遗留问题
乐观锁造成的库存遗留问题
a.Lua脚本
Lua是一个小巧的脚本语言,Lua脚本很容易被C/C++代码调用,也可以反过来调用C/C++的函数,Lua并没有提供强大的库,一个完整的Lua解释器不过200k,所以Lua不适合作为开发独立应用程序的语言,而是作为嵌入式脚本语言。
很多应用程序、游戏使用Lua作为自己的嵌入式脚本语言,以此来实现可配置性,可扩展性。
这其中包括魔兽争霸地图、魔兽世界、博德之门、愤怒的小鸟等众多游戏插件或外挂。
b.Lua脚本在Redis中的优势
将复杂的或者多步的redis操作,写为一个脚本,一次提交给redis执行,减少反复连接redis的次数。提升性能。
Lua脚本是类似redis事务,有一定的原子性,不会被其他命令插队,可以完成一些redis事务性的操作。
但是注意redis的Lua脚本的功能,只有在Redis2.6以上的版本才可以使用。
利用Lua脚本淘汰用户,解决超卖问题。
redis2.6版本以后,通过Lua脚本解决争抢问题,实际上是Redis利用其单线程的特性,用任务队列的方式解决多任务并发问题。
9.Redis持久化
9.1.总体介绍
Redis提供了2个不同形式的持久化方式
- RDB(Redis DataBase)
- AOF(Append Of File)
9.2.RDB(Redis DataBase)
9.2.1.是什么
在指定的时间间隔内将内存中的数据集快照写入磁盘,也就是行话讲的Snapshot快照,它恢复时是将快照文件直接读到内存里。
9.2.2.备份是如何执行的
Redis会单独创建(fork)一个子进程来进行持久化,会先将数据写入到一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件。
整个过程中,主进程是不进行任何IO操作的,这就确保了极高的性能,如果需要进行大规模的数据的恢复,且对于数据恢复的完整性不是非常敏感,那RDB方式要比AOF方式更加的高效。
RDB的缺点是,最后一次持久化的数据可能丢失。
9.2.3.Fork
- Fork的作用是复制一个与当前进程一样的进程。新的进程的所有数据(变量、环境变量、程序计数器等)数值都和原进程一致,但是是一个全新的进程,并作为原进程的子进程。
- 在Linux程序中,fork()会产生一个和父进程完成相同的子进程,但子进程在此后多会exec系统调用,出于效率考虑,Linux引入了“写时复制技术”。
- 一般情况,父进程和子进程会共同用一段物理内存,只有进程空间的各段内容要发生变化时,才会将父进程的内容复制一份给子进程里。
9.2.4.RDB持久化流程
9.2.5.dump.rdb文件
在redis.conf中配置文件名称,默认为dump.rdb。dbfilename dump.rdb
9.2.6.配置位置
rdb的文件保存位置,也可以修改。默认为Redis启动命令行所在的目录下。dir ./也可以自定义目录/myredis/
9.2.7.如何触发RDB快照:保持策略
9.2.7.1.配置文件中默认的快照配置
快照持久化操作的频次
1 | save 3600 1save 300 100save 60 10000# 当改变的key越多,持久化的间隔时间就越短 |
为了测试明显,跳转至380行附近,更改为如下:
1 | save 3600 1save 60 10 # 更改为,60秒内,有10次key的变化,就进行持久化操作save 60 10000 |
9.2.7.2.
9.2.7.3.
9.2.7.4.
9.2.7.5.
9.2.7.6.
9.2.7.7.
9.3.Redis持久化之AOF
10.Redis主从复制
11.Redis集群
 wechat
wechat alipay
alipay